Outline
TypeScript possesses the world’s most powerful type system and the most expansive ecosystem.
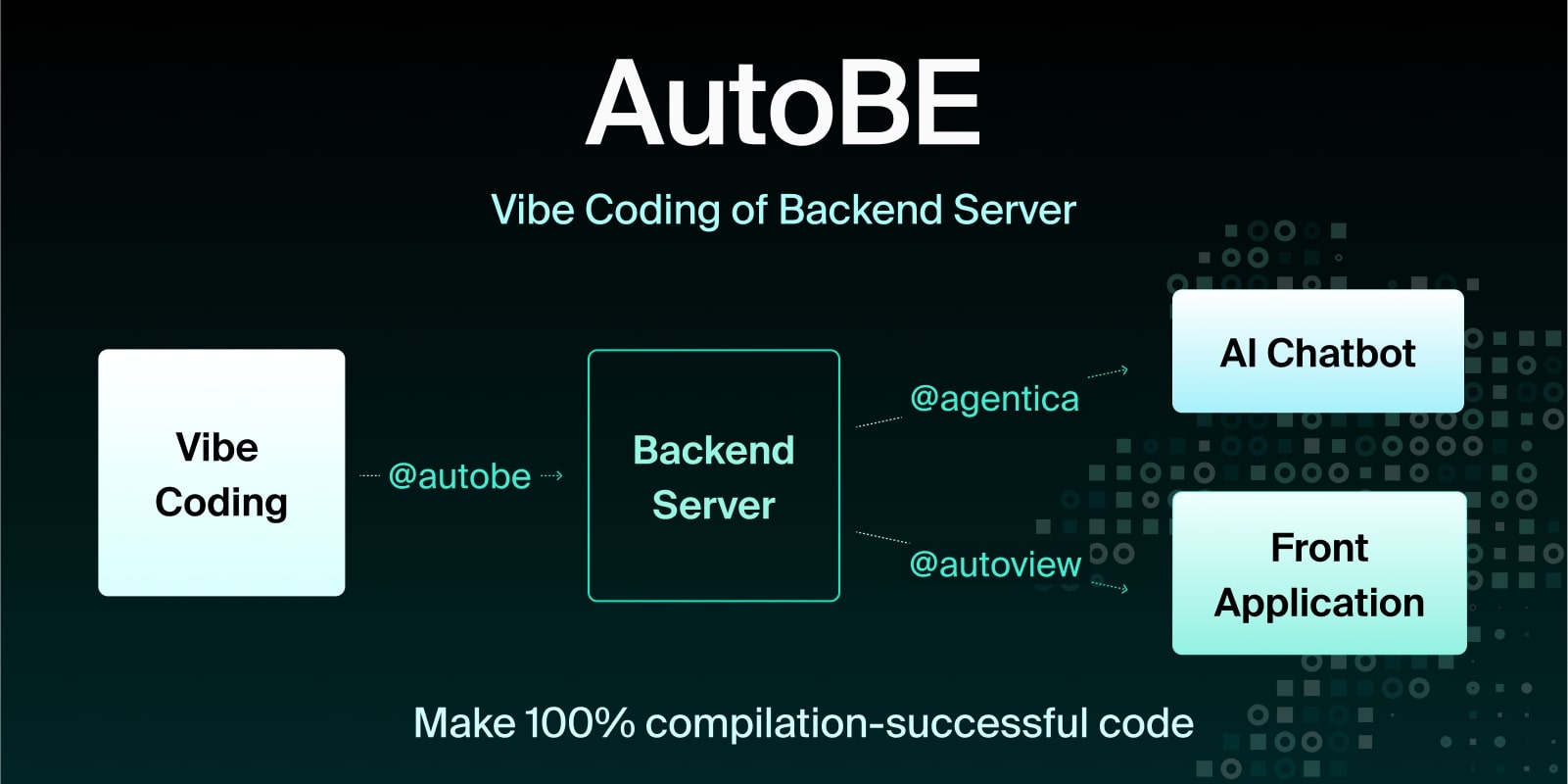
The AI-powered no-code agent @autobe generates backend applications written in TypeScript. The reason @autobe adopted TypeScript is because of its powerful compiler support, plugin system capabilities, and vast ecosystem.
First, TypeScript has the most powerful and strict type system among existing backend languages, and it’s the only one in the world that can embed its compiler in applications and utilize it at the API level. When validating AI-generated code, being able to guarantee stability at the compiler level is extremely important. And this compiler must be available at the API level so that agents can continuously validate AI-written code and provide compilation errors as feedback to the LLM for improvement.
Second, TypeScript’s plugin system enables powerful compiler extensions that are crucial for AI-driven development workflows. @autobe extensively leverages AI function calling through complex AST (Abstract Syntax Tree) structures, and uses TypeScript’s plugin system via the typia library to automatically convert TypeScript types into AI function calling schemas. This eliminates the operational complexity of manually managing intricate JSON schemas for AI function calling.
Additionally, TypeScript (JavaScript) has the world’s largest ecosystem. One language can develop backend servers, front/mobile/desktop applications, and even AI agents. In fact, @autobe developed both its Agent system and Playground application entirely in TypeScript. Furthermore, @agentica which transforms backend applications generated by @autobe into AI chatbots, and @autoview which converts them into frontend applications, were all developed based on the TypeScript language characteristics.
Powerful Type System
![]()
TypeScript possesses the most powerful type system among existing backend languages, providing the revolutionary advantage of ensuring backend server application stability at compile time to a significant degree. Without actually running the server and performing runtime tests, TypeScript’s compiler can verify the type safety of code and discover potential errors in advance.
For no-code AI agents, this compile-time validation capability is absolutely critical. AI-generated code often contains subtle errors, inconsistencies, or type mismatches that would be difficult to detect through manual review. With TypeScript’s compile-time verification, these issues can be caught immediately during the code generation process, allowing the AI agent to iteratively refine the code until it passes all type checks. This creates a tight feedback loop where the AI can learn from compilation errors and continuously improve the generated code quality without requiring expensive runtime testing or manual debugging sessions.
This difference becomes stark when compared to other backend languages. Languages like Java, Python, Ruby, and Go lack TypeScript’s sophisticated type system, making it difficult to be confident that code is correctly written until actually running the server application and performing runtime tests in various scenarios. Particularly for dynamically typed languages like Python or Ruby, type-related errors are frequently discovered only in production environments.
TypeScript’s type system can verify the correctness of complex business logic at compile time through advanced features such as Structural Typing, Conditional Types, Template Literal Types, and Mapped Types. This type system is so powerful that it has been proven to be Turing Complete, reaching a level where programming is possible at the type level.
For more detailed information about TypeScript’s type system features, refer to the official documentation (https://www.typescriptlang.org/docs/handbook/2/types-from-types.html ) and TypeScript Deep Dive (https://basarat.gitbook.io/typescript/ ).
Most importantly, TypeScript fully exposes its compiler API for programmatic access. This enables real-time validation of AI-generated code and allows compilation errors to be provided as feedback to LLMs for code improvement. This characteristic is an essential feature for AI-based code generation tools like @autobe, and represents a unique strength of TypeScript not found in other languages.
Plugin System
![]()
TypeScript’s plugin system enables powerful compiler extensions that are crucial for AI-driven development workflows.
@autobe extensively leverages AI function calling across all domains. Rather than having AI generate programming code as raw text, @autobe employs a sophisticated approach where AI generates our custom-designed AST (Abstract Syntax Tree) structures through function calling. This AST data is then validated and used to provide feedback to the AI, with the final completed AST being transformed into Prisma/TypeScript code.
The AST structures used by @autobe are incredibly deep and complex in their hierarchy, requiring extensive and intricate descriptions to help AI understand the context. Managing JSON schemas for AI function calling through traditional development methodologies—whether hand-written or duplicated through reflection—would be operationally unfeasible given this complexity.
AutoBeDatabase.IApplication: AST structure for Prisma database schema designAutoBeOpenApi.IDocument: AST structure for RESTful API design
To solve this challenge, @autobe utilizes TypeScript’s plugin system through the typia library, which extends compilation capabilities by automatically converting TypeScript types into AI function calling schemas. typia analyzes TypeScript source code at the compiler level and automatically generates appropriate AI function calling schemas for each AST type.
This represents another decisive factor in why the WrtnLabs team chose TypeScript for @autobe development.
Schema Generation
import { AutoBeOpenApi, AutoBeDatabase } from "@autobe/prisma";
import { ILlmApplication } from "@samchon/openapi";
import typia from "typia";
const app: ILlmApplication<"chatgpt"> = typia.llm.application<
ICodeGenerator,
"chatgpt",
{ reference: true }
>();
console.log(app);
interface ICodeGenerator {
/**
* Generate Prisma AST application for database schema design.
*/
generatePrismaSchema(app: AutoBeDatabase.IApplication): void;
/**
* Generate OpenAPI document for RESTful API design.
*/
generateOpenApiDocument(app: AutoBeOpenApi.IDocument): void;
}Expansive Ecosystem
TypeScript is the only programming language that enables development of backend servers, frontend web applications, mobile apps, desktop applications, and even AI agents with a single language. This versatility goes beyond mere possibility, recording overwhelming market share in each field.
In the web frontend field, JavaScript/TypeScript holds virtually 100% market share, and backend development through Node.js has become mainstream technology adopted by 43% of Fortune 500 companies. In mobile application development, React Native powers apps with billions of users including Facebook, Instagram, and Discord, while in desktop applications, Electron-based VS Code, Slack, and Discord have established themselves as leading applications in their respective fields. Even in AI agent development, major frameworks like Vercel AI SDK and LangChain.js have adopted TypeScript as their primary language, showing rapid growth.
The NPM ecosystem holds over 2.5 million packages and records 184 billion downloads monthly, making it the world’s largest software repository - larger than all other programming language package managers combined. According to GitHub statistics, TypeScript is the third most used language as of 2024, with 78% of JavaScript developers using TypeScript.
This ecosystem’s vastness and integration had a decisive impact on building WrtnLabs’ no-code ecosystem. @autobe developed both its Agent system and Playground UI application in TypeScript as a single language, providing significant advantages in code sharing, type safety, and development efficiency. Furthermore, @agentica, which transforms backend applications generated by @autobe into AI chatbots, and @autoview, which converts them into frontend applications, were all developed based on TypeScript.
It’s no coincidence that the entire no-code ecosystem developed by the WrtnLabs team was built on TypeScript. TypeScript’s powerful type system ensures the stability of AI-generated code, its vast ecosystem enables immediate utilization of all necessary features, and the ability to develop the entire stack with a single language significantly reduces development complexity. This demonstrates that TypeScript was an indispensable choice in realizing WrtnLabs’ vision that “anyone who can converse can become a full-stack developer.”