AI Function Calling
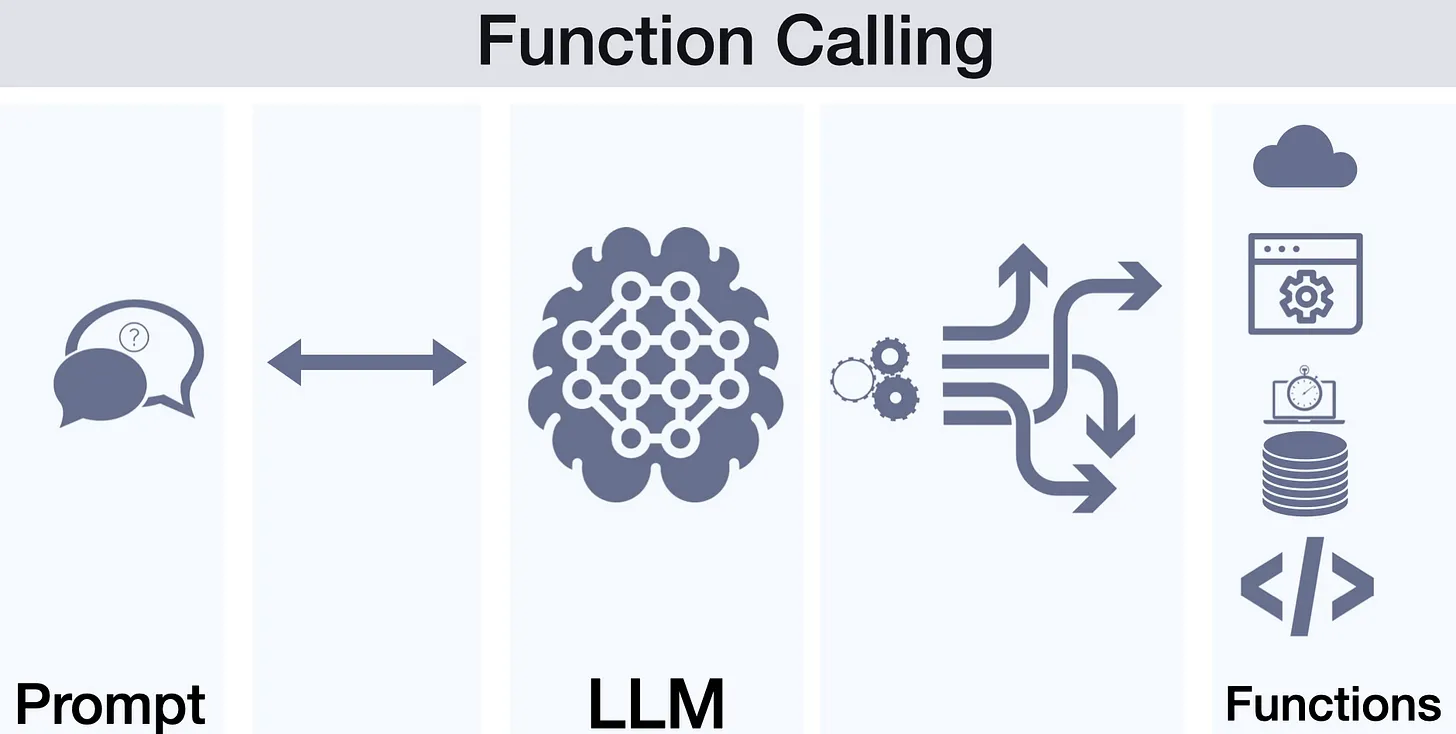
@autobe fundamentally prefers AI function calling to generate AST (Abstract Syntax Tree) data over having AI write raw programming code as text. The system validates the AST data generated through AI function calling, provides feedback to the AI for correction when errors are detected, and finally converts the validated AST data into actual programming code.
Therefore, the success of @autobe depends on three critical factors. First, how precisely and efficiently we can create AI function calling schemas. Second, how detailed and accurate validation feedback we can provide to the AI when it generates incorrect AST data. Finally, how clearly we can communicate the coding rules that @autobe must follow while constructing code (composing AST data) to the AI.
To address these challenges, @autobe adopts typia to generate AI function calling schemas at the compiler level. The compiler integrated with typia not only creates AI function calling schemas but also generates validation functions for each type. Moreover, the coding rules that @autobe must follow are embedded as comments in each AST type. These comments are recorded as type descriptions when typia converts TypeScript types into AI function calling schemas.
This approach creates a comprehensive development story that ensures both type safety and rule compliance through compiler-driven automation.
Schema Made by Compiler
Schema Generation
import { AutoBeOpenApi, AutoBeDatabase } from "@autobe/prisma";
import { ILlmApplication } from "@samchon/openapi";
import typia from "typia";
const app: ILlmApplication<"chatgpt"> = typia.llm.application<
ICodeGenerator,
"chatgpt",
{ reference: true }
>();
console.log(app);
interface ICodeGenerator {
/**
* Generate Prisma AST application for database schema design.
*/
generatePrismaSchema(app: AutoBeDatabase.IApplication): void;
/**
* Generate OpenAPI document for RESTful API design.
*/
generateOpenApiDocument(app: AutoBeOpenApi.IDocument): void;
generateTestFunction(func: AutoBeTest.IFunction): void;
}undefined
import { tags } from "typia";
import { CamelCasePattern } from "../typings";
import { SnakeCasePattern } from "../typings/SnakeCasePattern";
/**
* AST types for Prisma schema generation via AI function calling.
*
* Hierarchy: IApplication → IFile → IModel → Fields + Indexes.
*
* @author Samchon
*/
export namespace AutoBeDatabase {
/** Root container for the entire database schema. */
export interface IApplication {
/** Array of schema files, each covering a business domain. */
files: IFile[];
}
/** A single Prisma schema file covering one business domain. */
export interface IFile {
/**
* Filename following "schema-{number}-{domain}.prisma" convention. The
* number indicates dependency order.
*/
filename: string & tags.Pattern<"^[a-zA-Z0-9._-]+\\.prisma$">;
/**
* Business domain namespace used in Prisma @namespace directives.
*
* Use the exact snake_case component namespace. This namespace is not a
* table-name prefix by itself; table prefixes come from the configured
* database prefix and table naming rules.
*/
namespace: string;
/** Models (database tables) within this domain. */
models: IModel[] & tags.MinItems<1>;
}
/** A single Prisma model (database table). */
export interface IModel {
/**
* Final table/model name.
*
* Use a plural, snake_case, prefix-aware table name. When `stance` is
* "material", place the special `mv_` prefix before the configured database
* prefix.
*/
name: string & SnakeCasePattern;
/**
* Finished Prisma documentation for this model. Include only business prose
* about the stored concept, lifecycle, ownership, and important
* relationships.
*/
description: string;
/**
* Architectural role of this model, guiding API endpoint generation.
*
* - "primary": Core entity users manage independently (full CRUD APIs). Use
* when users need to create, search, or manage entities outside their
* parent context.
* - "actor": Authenticated user type with its own identity, credentials, and
* auth flow. Generates auth endpoints.
* - "session": Login session table belonging to exactly one actor.
* Append-only audit trail, managed via auth flows.
* - "subsidiary": Supporting entity managed through its parent, rarely needs
* standalone endpoints.
* - "snapshot": Point-in-time versioning record, typically append-only and
* read-only from user perspective.
* - "material": Read-only materialized query projection. The table name must
* start with `mv_`, and normal CRUD endpoints are not generated.
*/
stance:
| "primary"
| "subsidiary"
| "snapshot"
| "material"
| "actor"
| "session";
/**
* User message file identifiers referenced while deriving this model.
*
* This internal trace is assigned by ontology orchestration after
* function-calling output is accepted. Database schema agents must not
* write it.
*
* @internal
*/
reference_file_ids?: Array<string & tags.Format<"uuid">>;
//----
// FIELDS
//----
/** Primary key field (UUID). */
primaryField: IPrimaryField;
/** Foreign key fields establishing relationships to other models. */
foreignFields: IForeignField[];
/**
* Regular persisted data fields owned by this row, including values that a
* snapshot/history row intentionally captures at a point in time.
*
* Every model must include a non-null `created_at` datetime plain field.
* Mutable business rows also include non-null `updated_at`, while
* `deleted_at` is added only for soft-delete requirements. Current
* query/service output reconstructed from source rows belongs in prose or
* materialized views instead.
*/
plainFields: IPlainField[];
//----
// INDEXES
//----
/** Unique indexes for data integrity constraints. */
uniqueIndexes: IUniqueIndex[];
/** Regular indexes for query performance. */
plainIndexes: IPlainIndex[];
/** GIN indexes for PostgreSQL full-text search (trigram). */
ginIndexes: IGinIndex[];
}
/** Primary key field of a model. */
export interface IPrimaryField {
/** MUST be exactly `id`; do not use a table-specific primary key name. */
name: string & SnakeCasePattern;
/** Primary keys are always UUID values. */
type: "uuid";
/** Finished Prisma documentation for this primary key field. */
description: string;
/**
* @ignore
* @internal
*/
nullable?: boolean;
}
/** Foreign key field establishing a relationship to another model. */
export interface IForeignField {
/** MUST use snake_case. Convention: "{target_model}_id". */
name: string & SnakeCasePattern;
type: "uuid";
/**
* Finished Prisma documentation for this relationship field. Include only
* business prose about the referenced concept and why this table needs it.
*/
description: string;
/** Prisma relation configuration. */
relation: IRelation;
/** True for 1:1 relationships, false for 1:N. */
unique: boolean;
/**
* True only when this row can legitimately exist without the referenced
* row. Use required foreign keys only for parents or owners that must exist
* before this row is created.
*/
nullable: boolean;
}
/** Prisma @relation configuration for a foreign key. */
export interface IRelation {
/** Relation property name in this model. MUST use camelCase. */
name: string & CamelCasePattern;
/** Must match an existing model name in the schema. */
targetModel: string;
/**
* Inverse relation property name generated in the target model. Typically
* plural for 1:N (e.g., "comments"), singular for 1:1.
*/
oppositeName: string & CamelCasePattern;
/**
* Explicit Prisma mapping name. Only needed for self-referential relations
* or when auto-generated names conflict.
*
* @internal
*/
mappingName?: string;
}
/** A regular data field (not a primary or foreign key). */
export interface IPlainField {
/** MUST use snake_case. */
name: string & SnakeCasePattern;
/**
* Prisma/PostgreSQL type mapping: boolean, int, double, string, uri, uuid
* (non-FK), datetime, email, ipv4.
*/
type:
| "boolean"
| "int"
| "double"
| "string"
| "uri"
| "uuid"
| "datetime"
| "email"
| "ipv4";
/**
* Finished Prisma documentation for this persisted data field. Include only
* business prose about the stored value, lifecycle meaning, and requirement
* purpose. If the value is current output reconstructed from other source
* rows, keep it out of plainFields unless the row explicitly materializes
* it.
*/
description: string;
/**
* True only when Analyze, raw-file evidence, or workflow timing says the
* stored value may be absent. Required temporal fields and system
* invariants must remain non-null.
*/
nullable: boolean;
}
/** Unique index constraint (@@unique). */
export interface IUniqueIndex {
/** Field names forming the unique constraint. All must exist in the model. */
fieldNames: string[] & tags.MinItems<1> & tags.UniqueItems;
/** Always true. Distinguishes from plain indexes. */
unique: true;
}
/** Regular index for query performance (@@index). */
export interface IPlainIndex {
/** Field names to index. Order matters for composite indexes. */
fieldNames: string[] & tags.MinItems<1> & tags.UniqueItems;
}
/** GIN index for PostgreSQL full-text search (gin_trgm_ops). */
export interface IGinIndex {
/** Must be a string field containing searchable text. */
fieldName: string;
}
}undefined
import { tags } from "typia";
import { CamelCasePattern } from "../typings/CamelCasePattern";
/**
* AST for OpenAPI v3.1 specification generation via AI function calling.
*
* Simplified from full OpenAPI to remove ambiguous/duplicated expressions while
* maintaining type safety for AI-driven code generation.
*
* @author Samchon
*/
export namespace AutoBeOpenApi {
/* -----------------------------------------------------------
DOCUMENT
----------------------------------------------------------- */
/**
* Root document for Restful API operations and components.
*
* Corresponds to the top-level OpenAPI structure, containing all API
* operations and reusable component schemas.
*/
export interface IDocument {
/**
* List of API operations.
*
* Combination of {@link AutoBeOpenApi.IOperation.path} and
* {@link AutoBeOpenApi.IOperation.method} must be unique.
*
* @minItems 1
*/
operations: AutoBeOpenApi.IOperation[];
/**
* Reusable components referenced by API operations.
*
* Type naming conventions for schemas:
*
* - `IEntityName`: Full detailed entity (e.g., `IShoppingSale`)
* - `IEntityName.ICreate`: Request body for POST creation
* - `IEntityName.IUpdate`: Request body for PUT update
* - `IEntityName.IRequest`: Search/filter/pagination parameters
* - `IEntityName.ISummary`: Simplified view for list operations
* - `IEntityName.IAbridge`: Intermediate detail level
* - `IEntityName.IInvert`: Alternative perspective of an entity
* - `IPageIEntityName`: Paginated results with `pagination` and `data`
*/
components: AutoBeOpenApi.IComponents;
}
/**
* Single API endpoint with method, path, parameters, and request/response.
*
* All request/response bodies must be object types referencing named
* components. Content-type is always `application/json`. For file
* upload/download, use `string & tags.Format<"uri">` instead of binary.
*/
export interface IOperation extends IEndpoint {
/**
* Internal implementation guidance for downstream agents (Realize, Test).
*
* Describe HOW this operation should be implemented: service logic, DB
* queries, business rules, edge cases, and error handling.
*
* > MUST be written in English. Never use other languages.
*/
specification: string;
/**
* API documentation for consumers. Describe the operation's purpose,
* business logic, relationships, and error handling.
*
* Format: summary sentence first, `\n\n`, then paragraphs grouped by topic.
* Reference DB schema table/column descriptions for consistency.
*
* Do NOT use "soft delete" / "soft-delete" unless the operation actually
* implements soft deletion (triggers validation expecting
* soft_delete_column).
*
* > MUST be written in English. Never use other languages.
*/
description: string;
/**
* Exact database model name primarily represented by this operation.
*
* When present, this value is copied from the upstream endpoint design and
* must match an AutoBeDatabase model name exactly, such as
* `shopping_sale_snapshots`. Use `null` for workflow, report, aggregate,
* cross-model, or purely computed operations without one primary model.
*/
databaseSchema: string | null;
/**
* Authorization type of the API operation.
*
* - `"login"`: Credential validation operations
* - `"join"`: Account registration operations
* - `"refresh"`: Token renewal operations
* - `null`: All other operations
*/
authorizationType: "login" | "join" | "refresh" | null;
/**
* List of path parameters.
*
* Each parameter name must correspond to a `{paramName}` in the
* {@link path}.
*/
parameters: AutoBeOpenApi.IParameter[];
/** Request body of the API operation, or `null` if none. */
requestBody: AutoBeOpenApi.IRequestBody | null;
/** Response body of the API operation, or `null` if none. */
responseBody: AutoBeOpenApi.IResponseBody | null;
/**
* Authorization actor required to access this API operation.
*
* MUST use camelCase. The actor name MUST match exactly with a user
* type/table defined in the database schema.
*
* Set to `null` for public endpoints requiring no authentication.
*/
authorizationActor: (string & CamelCasePattern & tags.MinLength<1>) | null;
/**
* Functional name of the API endpoint. MUST use camelCase.
*
* MUST NOT be a JS/TS reserved word (`delete`, `for`, `if`, `class`,
* `return`, `new`, `this`, `void`, `const`, `let`, `var`, `async`, `await`,
* `export`, `import`, `switch`, `case`, `throw`, `try`). Use `erase`
* instead of `delete`, `iterate` instead of `for`.
*
* Standard names:
*
* - `index`: list/search (PATCH), `at`: get by ID (GET)
* - `create`: POST, `update`: PUT, `erase`: DELETE
*
* Accessor uniqueness: the accessor is formed by joining non-parameter path
* segments with dots, then appending the name. E.g., path
* `/shopping/sale/{saleId}/review/{reviewId}` + name `at` = accessor
* `shopping.sale.review.at`. Must be globally unique.
*/
name: string & CamelCasePattern;
/**
* Prerequisites: API operations that must succeed before this one.
*
* ONLY for business logic dependencies (resource existence, state checks,
* data availability). NEVER for authentication -- use `authorizationActor`
* instead.
*
* Prerequisites are executed in array order; all must return 2xx before the
* main operation proceeds.
*
* @see {@link IPrerequisite}
*/
prerequisites: IPrerequisite[];
/**
* Accessor of the operation.
*
* If you configure this property, the assigned value will be used as
* {@link IHttpMigrateRoute.accessor}. Also, it can be used as the
* {@link IHttpLlmFunction.name} by joining with `.` character in the LLM
* function calling application.
*
* Note that the `x-samchon-accessor` value must be unique in the entire
* OpenAPI document operations. If there are duplicated `x-samchon-accessor`
* values, {@link IHttpMigrateRoute.accessor} will ignore all duplicated
* `x-samchon-accessor` values and generate the
* {@link IHttpMigrateRoute.accessor} by itself.
*
* @internal
*/
accessor?: string[] | undefined;
}
/**
* Authorization definition for an actor type.
*
* Uses `Authorization: Bearer <token>` header only. The token is guaranteed
* to include the authenticated actor's `id` field.
*/
export interface IAuthorization {
/**
* Actor name in camelCase. MUST exactly match a table name in the database
* schema representing this user type.
*/
name: string & CamelCasePattern;
/**
* Description of this authorization actor's purpose and capabilities.
*
* > MUST be written in English. Never use other languages.
*/
description: string;
}
/** Path parameter definition for an API route. */
export interface IParameter {
/**
* Description of the path parameter.
*
* > MUST be written in English. Never use other languages.
*/
description: string;
/**
* Identifier name in camelCase. Must match the `{paramName}` in the
* {@link AutoBeOpenApi.IOperation.path}.
*/
name: string & CamelCasePattern;
/** Type schema of the path parameter (primitive types only). */
schema:
| AutoBeOpenApi.IJsonSchema.IInteger
| AutoBeOpenApi.IJsonSchema.INumber
| AutoBeOpenApi.IJsonSchema.IString;
}
/**
* Request body for an API operation.
*
* Content-type is always `application/json`. For file uploads, use a URI
* string property instead of `multipart/form-data`.
*/
export interface IRequestBody {
/**
* Description of the request body.
*
* > MUST be written in English. Never use other languages.
*/
description: string;
/**
* Type name referencing a component schema.
*
* Naming convention: `IEntityName.ICreate` (POST), `IEntityName.IUpdate`
* (PUT), `IEntityName.IRequest` (list/search).
*/
typeName: string;
}
/**
* Response body for an API operation.
*
* Content-type is always `application/json`. For file downloads, use a URI
* string property instead of `application/octet-stream`.
*/
export interface IResponseBody {
/**
* Description of the response body.
*
* > MUST be written in English. Never use other languages.
*/
description: string;
/**
* Type name referencing a component schema.
*
* Naming convention: `IEntityName` (full), `IEntityName.ISummary`,
* `IEntityName.IInvert`, `IPageIEntityName` (paginated).
*/
typeName: string;
}
/* -----------------------------------------------------------
JSON SCHEMA
----------------------------------------------------------- */
/** Reusable named DTO schemas and security schemes. */
export interface IComponents {
/**
* Named DTO schemas.
*
* Type naming conventions:
*
* - `IEntityName`: Full detailed entity
* - `IEntityName.ICreate`: POST request body
* - `IEntityName.IUpdate`: PUT request body
* - `IEntityName.ISummary`: Simplified list view
* - `IEntityName.IRequest`: Search/filter parameters
* - `IEntityName.IInvert`: Alternative perspective
* - `IPageIEntityName`: Paginated results (`pagination` + `data`)
*/
schemas: Record<string, IJsonSchemaDescriptive>;
/** Authorization schemes for authenticated actors. */
authorizations: IAuthorization[];
}
/**
* JSON Schema type following OpenAPI v3.1 (simplified).
*
* CRITICAL: Union types MUST use `IOneOf`. NEVER use array in `type` field.
*
* Wrong: `{ type: ["string", "null"] }` Correct: `{ oneOf: [{ type: "string"
* }, { type: "null" }] }`
*
* The `type` field is a discriminator and MUST be a single string value.
*/
export type IJsonSchema =
| IJsonSchema.IConstant
| IJsonSchema.IBoolean
| IJsonSchema.IInteger
| IJsonSchema.INumber
| IJsonSchema.IString
| IJsonSchema.IArray
| IJsonSchema.IObject
| IJsonSchema.IReference
| IJsonSchema.IOneOf
| IJsonSchema.INull;
export namespace IJsonSchema {
/** Constant value type. */
export interface IConstant {
/** The constant value. */
const: boolean | number | string;
}
/** Boolean type info. */
export interface IBoolean extends ISignificant<"boolean"> {}
/** Integer type info. */
export interface IInteger extends ISignificant<"integer"> {
/** @type int64 */
minimum?: number;
/** @type int64 */
maximum?: number;
/** @type int64 */
exclusiveMinimum?: number;
/** @type int64 */
exclusiveMaximum?: number;
/**
* @type uint64
* @exclusiveMinimum 0
*/
multipleOf?: number;
}
/** Number (double) type info. */
export interface INumber extends ISignificant<"number"> {
minimum?: number;
maximum?: number;
exclusiveMinimum?: number;
exclusiveMaximum?: number;
/** @exclusiveMinimum 0 */
multipleOf?: number;
}
/** String type info. */
export interface IString extends ISignificant<"string"> {
/** Format restriction. */
format?:
| "password"
| "regex"
| "uuid"
| "email"
| "hostname"
| "idn-email"
| "idn-hostname"
| "iri"
| "iri-reference"
| "ipv4"
| "ipv6"
| "uri"
| "uri-reference"
| "uri-template"
| "url"
| "date-time"
| "date"
| "time"
| "duration"
| "json-pointer"
| "relative-json-pointer";
/** Pattern restriction. */
pattern?: string;
/**
* Content media type restriction.
*
* For multiple media types, use `oneOf` with separate string schemas per
* `contentMediaType` value. Never use an array here.
*/
contentMediaType?: string;
/** @type uint64 */
minLength?: number;
/** @type uint64 */
maxLength?: number;
}
/** Array type info. */
export interface IArray extends ISignificant<"array"> {
/** Type schema of array elements. */
items: Exclude<IJsonSchema, IJsonSchema.IObject>;
/** If `true`, array elements must be unique. */
uniqueItems?: boolean;
/** @type uint64 */
minItems?: number;
/** @type uint64 */
maxItems?: number;
}
/** Object type info. */
export interface IObject extends ISignificant<"object"> {
/** @ignore */
"x-autobe-database-schema"?: string | null | undefined;
/** Key-value pairs of the object's named properties. */
properties: Record<string, IJsonSchema>;
/**
* Schema for dynamic keys (`Record<string, T>`), or `false` if no
* additional properties are allowed.
*/
additionalProperties?: false | Exclude<IJsonSchema, IJsonSchema.IObject>;
/**
* Property keys that must be present. Properties not listed here are
* optional.
*/
required: string[];
}
/** Reference type directing named schema. */
export interface IReference {
/**
* JSON Pointer reference to a named schema (e.g.,
* `#/components/schemas/SomeObject`).
*/
$ref: string;
}
/**
* Union type.
*
* `IOneOf` represents a union type in TypeScript (`A | B | C`).
*
* For reference, even though your Swagger (or OpenAPI) document has defined
* `anyOf` instead of the `oneOf`, {@link AutoBeOpenApi} forcibly converts it
* to `oneOf` type.
*/
export interface IOneOf {
/** List of the union types. */
oneOf: Exclude<IJsonSchema, IJsonSchema.IOneOf | IJsonSchema.IObject>[];
/** Discriminator info of the union type. */
discriminator?: IOneOf.IDiscriminator;
}
export namespace IOneOf {
/** Discriminator info of the union type. */
export interface IDiscriminator {
/** Property name for the discriminator. */
propertyName: string;
/**
* Mapping of the discriminator value to the schema name.
*
* This property is valid only for {@link IReference} typed
* {@link IOneOf.oneOf} elements. Therefore, `key` of `mapping` is the
* discriminator value, and `value` of `mapping` is the schema name like
* `#/components/schemas/SomeObject`.
*/
mapping?: Record<string, string>;
}
}
/** Null type. */
export interface INull extends ISignificant<"null"> {}
interface ISignificant<Type extends string> {
/**
* Discriminator value. MUST be a single string, NEVER an array.
*
* For nullable types, use `IOneOf` instead: `{ oneOf: [{ type: "string"
* }, { type: "null" }] }`
*/
type: Type;
}
}
/**
* Descriptive type schema info with required documentation.
*
* `AutoBeOpenApi.IJsonSchemaDescriptive` extends the base JSON schema types
* with a required `description` field for API documentation. For object
* types, it also includes an `x-autobe-specification` field for
* implementation guidance.
*
* @ignore
*/
export type IJsonSchemaDescriptive =
| IJsonSchemaDescriptive.IConstant
| IJsonSchemaDescriptive.IBoolean
| IJsonSchemaDescriptive.IInteger
| IJsonSchemaDescriptive.INumber
| IJsonSchemaDescriptive.IString
| IJsonSchemaDescriptive.IArray
| IJsonSchemaDescriptive.IObject
| IJsonSchemaDescriptive.IReference
| IJsonSchemaDescriptive.IOneOf
| IJsonSchemaDescriptive.INull;
export namespace IJsonSchemaDescriptive {
export interface IConstant extends IDescriptive, IJsonSchema.IConstant {}
export interface IBoolean extends IDescriptive, IJsonSchema.IBoolean {}
export interface IInteger extends IDescriptive, IJsonSchema.IInteger {}
export interface INumber extends IDescriptive, IJsonSchema.INumber {}
export interface IString extends IDescriptive, IJsonSchema.IString {}
export interface IArray extends IDescriptive, IJsonSchema.IArray {}
export interface IObject extends IDescriptive, IJsonSchema.IObject {
properties: Record<string, IJsonSchemaProperty>;
}
export interface IReference extends IDescriptive, IJsonSchema.IReference {}
export interface IOneOf extends IDescriptive, IJsonSchema.IOneOf {}
export interface INull extends IDescriptive, IJsonSchema.INull {}
interface IDescriptive {
"x-autobe-specification"?: string | undefined;
description: string;
}
}
/**
* Type schema for object properties with implementation specifications.
*
* `IJsonSchemaProperty` extends the base JSON Schema types with
* implementation specifications. Each property in an
* {@link IJsonSchema.IObject object schema} uses this type.
*
* @ignore
*/
export type IJsonSchemaProperty =
| IJsonSchemaProperty.IConstant
| IJsonSchemaProperty.IBoolean
| IJsonSchemaProperty.IInteger
| IJsonSchemaProperty.INumber
| IJsonSchemaProperty.IString
| IJsonSchemaProperty.IArray
| IJsonSchemaProperty.IReference
| IJsonSchemaProperty.IOneOf
| IJsonSchemaProperty.INull;
export namespace IJsonSchemaProperty {
export interface IConstant extends IProperty, IJsonSchema.IConstant {}
export interface IBoolean extends IProperty, IJsonSchema.IBoolean {}
export interface IInteger extends IProperty, IJsonSchema.IInteger {}
export interface INumber extends IProperty, IJsonSchema.INumber {}
export interface IString extends IProperty, IJsonSchema.IString {}
export interface IArray extends IProperty, IJsonSchema.IArray {}
export interface IReference extends IProperty, IJsonSchema.IReference {}
export interface IOneOf extends IProperty, IJsonSchema.IOneOf {}
export interface INull extends IProperty, IJsonSchema.INull {}
interface IProperty {
"x-autobe-database-schema-property"?: string | null | undefined;
"x-autobe-specification"?: string | undefined;
description: string;
}
}
/* -----------------------------------------------------------
BACKGROUNDS
----------------------------------------------------------- */
/** API endpoint information. */
export interface IEndpoint {
/**
* HTTP path of the API operation.
*
* Must start with `/`. Parameters use curly braces: `{paramName}`. Resource
* names in camelCase. No quotes, spaces, role prefixes (`/admin/`), or API
* version prefixes (`/api/v1/`).
*
* Allowed characters: letters, digits, `/`, `{`, `}`, `-`, `_`, `.`
*/
path: string & tags.Pattern<"^\\/[a-zA-Z0-9\\/_{}.-]*$">;
/**
* HTTP method (lowercase only).
*
* Use `patch` (not `get`) when a read operation needs a complex
* {@link requestBody}. `get` cannot have a request body.
*/
method: "get" | "post" | "put" | "delete" | "patch";
}
/**
* Prerequisite API operation that must succeed before the main operation.
*
* ONLY for business logic dependencies (resource existence, state checks,
* data availability). NEVER for authentication or authorization -- those are
* handled via `authorizationActor`.
*
* Keep prerequisite chains minimal. Descriptions should explain WHY the
* dependency is needed.
*/
export interface IPrerequisite {
/** The API endpoint that must be called first. */
endpoint: IEndpoint;
/**
* Why this prerequisite is required (specific condition or state).
*
* > MUST be written in English. Never use other languages.
*/
description: string;
}
}undefined
import { tags } from "typia";
import { AutoBeOpenApi } from "../openapi/AutoBeOpenApi";
import { CamelCasePattern } from "../typings/CamelCasePattern";
/**
* AST type system for programmatic E2E test function generation through AI
* function calling.
*
* This namespace defines a comprehensive Abstract Syntax Tree structure that
* enables AI agents to construct complete E2E test functions at the AST level.
* Each type corresponds to specific TypeScript language constructs, allowing
* precise control over generated test code while maintaining type safety and
* business logic accuracy.
*
* ## Core Purpose
*
* The system is designed for systematic generation where AI function calls
* build test scenarios step-by-step, mapping business requirements to
* executable code. Instead of generating raw TypeScript strings, AI agents
* construct structured AST objects that represent:
*
* - Complete test function flows with proper data dependencies
* - Realistic API call sequences with captured responses
* - Comprehensive validation using TestValidator assertions
* - Complex business logic with conditional flows and error handling
*
* ## Architecture Overview
*
* - **IFunction**: Root container representing complete test functions
* - **Statements**: Building blocks for test logic (API operations, expressions,
* conditionals)
* - **Expressions**: Value computations, API calls, data access, and validations
* - **Literals**: Direct values for realistic business data
* - **Random Generators**: Dynamic test data creation with business constraints
* - **Predicates**: TestValidator assertions for comprehensive validation
*
* ## Business Context
*
* In E2E testing, this typically maps to complete business scenarios like:
*
* - Customer purchase workflows (registration → product selection → payment →
* confirmation)
* - Seller product management (authentication → product creation → inventory
* management)
* - Multi-role interactions (seller creates product → customer purchases → admin
* processes)
*
* Each generated function represents a realistic business workflow with proper
* data flow, where API responses from earlier steps provide inputs for
* subsequent operations, creating authentic test scenarios that mirror
* real-world application usage.
*
* @author Samchon
* @note This namespace documentation is excluded from AI function calling schemas
*/
export namespace AutoBeTest {
/**
* Root interface representing a complete E2E test function.
*
* This serves as the top-level container for all statements that comprise a
* test function. Each statement in the array represents a logical step in the
* test scenario, enabling systematic construction of complex business
* workflows through AI function calling.
*
* The generation process follows a three-stage approach: planning, drafting,
* and AST construction. This ensures that AI agents create well-structured,
* comprehensive test functions through deliberate design phases.
*
* In the context of E2E testing, this typically maps to complete business
* scenarios like "customer purchase flow" or "seller product management",
* where each statement handles one aspect of the workflow.
*/
export interface IFunction {
/**
* Strategic plan for implementing the test scenario.
*
* This field requires AI agents to think through the test implementation
* strategy before generating actual statements. It should analyze the given
* scenario and determine the optimal approach for creating a comprehensive
* test function.
*
* The plan should address:
*
* - Key business entities and their relationships that need to be tested
* - Sequence of operations required to achieve the test scenario
* - Data dependencies between different test steps
* - Validation points where business rules should be verified
* - Error conditions and edge cases that should be tested
* - Overall test structure and organization
*
* This planning step ensures that the generated statements follow a logical
* progression and create a realistic, comprehensive test scenario that
* properly validates the business workflow.
*/
plan: string;
/**
* Draft TypeScript code implementation of the test function.
*
* This field contains a preliminary TypeScript implementation of the test
* function based on the strategic plan. The draft serves as an intermediate
* step between planning and AST construction, allowing AI agents to:
*
* - Visualize the actual code structure before AST generation
* - Ensure proper TypeScript syntax and API usage patterns
* - Validate the logical flow and data dependencies
* - Identify any missing components or validation steps
* - Refine the approach before committing to AST statements
*
* The draft should be complete, executable TypeScript code that represents
* the full test function implementation. This code will then be analyzed
* and converted into the corresponding AST statements structure.
*
* **⚠️ CRITICAL: Avoid TypeScript features that complicate AST conversion!
* ⚠️**
*
* **❌ AVOID**: Template literals, destructuring, for/while loops, switch
* statements, try/catch blocks, spread operators, arrow functions without
* blocks
*
* **✅ USE**: Simple property access, explicit API operations, array methods
* (arrayMap, arrayForEach), predicate functions, clear if/else chains
*/
draft: string;
/**
* Array of statements that comprise the test function body.
*
* Each statement represents a discrete step in the test scenario, typically
* corresponding to business actions like API calls, validations, or state
* transitions. The order is significant as it reflects the logical flow of
* the business process.
*
* These statements should be generated by analyzing and converting the
* draft TypeScript code into structured AST representations, ensuring that
* the implementation follows the predetermined approach and creates a
* complete data flow chain representing the business scenario.
*
* **⚠️ CRITICAL: Convert unsupported TypeScript features to AutoBeTest AST
* equivalents! ⚠️**
*
* - Template literals → String concatenation with IBinaryExpression
* - Destructuring → Separate IPropertyAccessExpression statements
* - Loops → IArrayForEachExpression/IArrayMapExpression
* - Switch statements → Nested IIfStatement chains
* - Try/catch → IErrorPredicate for error testing
*
* **🚨 CRITICAL: DO NOT PUT EXPRESSIONS DIRECTLY IN STATEMENTS ARRAY! 🚨**
*
* This array ONLY accepts `IStatement` types. If you need to execute an
* expression (like predicates, function calls, etc.), you MUST wrap it in
* `IExpressionStatement`:
*
* **❌ WRONG - Expression directly in statements array**:
*
* ```typescript
* statements: [
* { type: "apiOperateStatement", ... },
* { type: "equalPredicate", ... } // ❌ This is IExpression, not IStatement!
* ]
* ```
*
* **✅ CORRECT - Expression wrapped in IExpressionStatement**:
*
* ```typescript
* statements: [
* { type: "apiOperateStatement", ... },
* {
* type: "expressionStatement", // ✅ Statement wrapper
* expression: {
* type: "equalPredicate", ... // ✅ Expression properly contained
* }
* }
* ]
* ```
*
* **Statement Types (can go directly in array)**:
*
* - `IApiOperateStatement`
* - `IExpressionStatement`
* - `IIfStatement`
* - `IReturnStatement`
* - `IThrowStatement`
*
* **Expression Types (must be wrapped in IExpressionStatement)**:
*
* - `IEqualPredicate`, `IConditionalPredicate`, `IErrorPredicate`, etc.
* - `ICallExpression`
* - All literal types and random generators
* - Any other `IExpression` type
*
* AI function calling strategy: Build statements by parsing the draft code
* and converting each logical operation into appropriate AST statement
* types, maintaining the data dependencies and business logic flow
* established in the draft. Always verify that you're using statement
* types, not expression types directly.
*/
statements: IStatement[] & tags.MinItems<1>;
}
/* -----------------------------------------------------------
STATEMENTS
----------------------------------------------------------- */
/**
* Union type representing all possible statement types in test functions.
*
* Statements are the building blocks of test function logic, each serving
* specific purposes in the E2E testing context:
*
* - IApiOperateStatement: Primary mechanism for all SDK API operations with
* automatic response handling and data capture
* - IExpressionStatement: Execute utility functions and validations without
* value capture
* - IIfStatement: Handle conditional business logic (prefer predicates for
* validation)
* - IReturnStatement: Function termination (rarely used in tests)
* - IThrowStatement: Explicit error scenarios
*
* Note: IBlockStatement is intentionally excluded from this union as it
* should only be used in special contexts (like if/else branches) rather than
* as a general statement type in the main function flow.
*
* AI selection strategy: Choose statement type based on the business action
* being performed. Use IApiOperateStatement for all API operations with
* automatic data capture, predicates for validations, and other statement
* types for specific non-API needs.
*/
export type IStatement =
| IApiOperateStatement
| IExpressionStatement
| IIfStatement
| IReturnStatement
| IThrowStatement;
/**
* Block for grouping statements in specific structural contexts.
*
* **SPECIAL USE ONLY**: This type represents a block of statements and should
* only be used in specific contexts where statement grouping is structurally
* required:
*
* - If/else statement branches
*
* - {@link IIfStatement.thenStatement}
* - {@link IIfStatement.elseStatement}
* - Arrow function bodies: {@link IArrowFunction.body}
* - Other contexts requiring explicit block scoping
*
* Unlike a block statement, this is not a statement itself but a structural
* container for statements. For normal test function flow, use individual
* statements directly rather than wrapping them in blocks.
*
* **Updated for API-first workflow**: Blocks can now contain
* `IApiOperateStatement` for API operations with automatic data capture,
* predicate expressions for validations, and other statement types as needed
* within conditional logic or function bodies.
*
* AI function calling restriction: Do not use for general statement grouping
* in main function flow. Reserve for structural requirements only
* (conditional branches, function bodies).
*/
export interface IBlock {
/** Type discriminator. */
type: "block";
/**
* Nested statements within this block.
*
* Each statement represents a step within the grouped operation. Can
* include any valid statement type:
*
* - `IApiOperateStatement` for API operations with automatic data capture
* within conditional logic
* - Predicate expressions for validations within blocks
* - Other statement types as needed for the block's purpose
*
* Maintains the same ordering significance as the root function's
* statements array.
*
* **🚨 CRITICAL: DO NOT PUT EXPRESSIONS DIRECTLY IN STATEMENTS ARRAY! 🚨**
*
* This array ONLY accepts `IStatement` types. If you need to execute an
* expression (like predicates, function calls, etc.), you MUST wrap it in
* `IExpressionStatement`:
*
* **❌ WRONG - Expression directly in statements array**:
*
* ```typescript
* statements: [
* { type: "apiOperateStatement", ... },
* { type: "conditionalPredicate", ... } // ❌ This is IExpression, not IStatement!
* ]
* ```
*
* **✅ CORRECT - Expression wrapped in IExpressionStatement**:
*
* ```typescript
* statements: [
* { type: "apiOperateStatement", ... },
* {
* type: "expressionStatement", // ✅ Statement wrapper
* expression: {
* type: "conditionalPredicate", ... // ✅ Expression properly contained
* }
* }
* ]
* ```
*
* **Statement Types (can go directly in array)**:
*
* - `IApiOperateStatement`
* - `IExpressionStatement`
* - `IIfStatement`
* - `IReturnStatement`
* - `IThrowStatement`
*
* **Expression Types (must be wrapped in IExpressionStatement)**:
*
* - `IEqualPredicate`, `IConditionalPredicate`, etc.
* - `ICallExpression`
* - All literal types and random generators
* - Any other `IExpression` type
*
* Example business context - Block: "Premium Customer Workflow"
*
* - API operation: Verify premium status (with automatic data capture)
* - API operation: Access exclusive content (with automatic data capture)
* - Predicate: Validate premium features are available (wrapped in
* expressionStatement)
* - API operation: Log premium usage (with automatic data capture)
*/
statements: IStatement[] & tags.MinItems<1>;
}
/**
* API operation statement for SDK function calls with automatic response
* handling and data capture.
*
* This statement type handles the complete lifecycle of API operations
* including:
*
* 1. Executing API function calls through the SDK
* 2. Automatically capturing the response in a variable (when variableName is
* provided)
* 3. Performing runtime type assertion using typia.assert<T>() for type safety
*
* This is the primary mechanism for all API interactions in E2E test
* scenarios, providing integrated data capture that eliminates the need for
* separate variable declarations.
*
* The statement automatically handles the complex pattern of API calling,
* response capturing, and type validation that is essential for robust E2E
* testing.
*
* AI function calling importance: Use this for ALL SDK API operations to
* ensure proper response handling, automatic data capture, and type safety in
* business test scenarios.
*/
export interface IApiOperateStatement {
/** Type discriminator. */
type: "apiOperateStatement";
/**
* API endpoint specification defining the operation to be called.
*
* Contains the HTTP method and path information that identifies which
* specific API operation from the OpenAPI specification should be invoked.
* This corresponds to operations defined in the AutoBeOpenApi.IDocument.
*
* The endpoint determines the expected parameter types, request body
* schema, and response body schema for proper type validation.
*/
endpoint: AutoBeOpenApi.IEndpoint;
/**
* Single argument object for the API function call.
*
* **CRITICAL**: All API functions accept exactly one object parameter that
* contains all necessary data for the operation. This argument object is
* constructed based on the API operation's specification and follows a
* standardized structure.
*
* **⚠️ CRITICAL AI RESTRICTION: This MUST be an AST expression, NOT a JSON
* value! ⚠️** **❌ WRONG: { "name": "John", "age": 30 } (raw JSON object)**
* **✅ CORRECT: IObjectLiteralExpression with proper AST structure**
*
* **Object Structure Rules:**
*
* The argument object is constructed by combining path parameters and
* request body data according to the following rules based on the target
* {@link AutoBeOpenApi.IOperation}:
*
* 1. **Path Parameters**: Each parameter from
* `AutoBeOpenApi.IOperation.parameters` becomes a property in the
* argument object, where:
*
* - Property name: `AutoBeOpenApi.IParameter.name`
* - Property value: Expression matching `AutoBeOpenApi.IParameter.schema`
* - Example: `{ saleId: "uuid-string", customerId: "another-uuid" }`
* 2. **Request Body**: If `AutoBeOpenApi.IOperation.requestBody` exists:
*
* - Add a `body` property containing the request body data
* - Value type: Object literal matching the requestBody's typeName schema
* - Example: `{ body: { name: "Product Name", price: 99.99 } }`
* 3. **Combined Structure**: When both path parameters and request body exist:
*
* ```typescript
* {
* // Path parameters as individual properties
* "saleId": "uuid-value",
* "customerId": "another-uuid",
* // Request body as 'body' property
* "body": {
* "name": "Updated Product",
* "price": 149.99,
* "description": "Enhanced product description"
* }
* }
* ```
*
* **Special Cases:**
*
* - **No Parameters**: When `parameters` is empty array AND `requestBody` is
* null, set this to `null` (the API function requires no arguments)
* - **Only Path Parameters**: When `requestBody` is null but `parameters`
* exist, create object with only path parameter properties
* - **Only Request Body**: When `parameters` is empty but `requestBody`
* exists, create object with only the `body` property
*
* **AI Construction Strategy:**
*
* 1. Analyze the target `AutoBeOpenApi.IOperation` specification
* 2. Extract all path parameters and create corresponding object properties
* 3. If request body exists, add it as the `body` property
* 4. Ensure all property values match the expected types from OpenAPI schema
* 5. Use realistic business data that reflects actual API usage patterns
*
* **Type Safety Requirements:**
*
* - Path parameter values must match their schema types (string, integer,
* etc.)
* - Request body structure must exactly match the referenced schema type
* - All required properties must be included with valid values
* - Optional properties can be omitted or included based on test scenario
* needs
*
* **Business Context Examples:**
*
* ```typescript
* // GET /customers/{customerId}/orders/{orderId} (no request body)
* {
* customerId: "cust-123",
* orderId: "order-456"
* }
*
* // POST /customers (only request body)
* {
* body: {
* name: "John Doe",
* email: "john@example.com",
* phone: "+1-555-0123"
* }
* }
*
* // PUT /customers/{customerId}/orders/{orderId} (both path params and body)
* {
* customerId: "cust-123",
* orderId: "order-456",
* body: {
* status: "shipped",
* trackingNumber: "TRACK123",
* estimatedDelivery: "2024-12-25"
* }
* }
*
* // GET /health (no parameters or body)
* null
* ```
*/
argument?: IObjectLiteralExpression | null;
/**
* Optional variable name for capturing the API response with automatic data
* handling.
*
* **Conditional Usage:**
*
* - `string`: When API operation returns data that needs to be captured
*
* - Creates: `const variableName: ApiResponseType =
* typia.assert<ResponseType>(await api.operation(...))`
* - The response is automatically type-validated using typia.assert
* - Variable can be referenced in subsequent test steps for data flow
* - `null`: When API operation returns void or response is not needed
*
* - Creates: `await api.operation(...)`
* - No variable assignment or type assertion is performed
* - Typically used for operations like delete, logout, or fire-and-forget
* calls
*
* **AI Decision Logic:**
*
* - Set to meaningful variable name when the response contains business data
* needed for subsequent operations
* - Set to null when the operation is void or side-effect only
* - Consider if subsequent test steps need to reference the response data for
* business logic or validations
*
* Variable naming should follow business domain conventions (e.g.,
* "customer", "order", "product") rather than technical naming. This
* automatic data capture eliminates the need for separate variable
* declaration statements.
*/
variableName?: (string & CamelCasePattern) | null;
}
/**
* Expression statement for executing utility operations without value
* capture.
*
* **IMPORTANT: For API operations, use `IApiOperateStatement` instead.** This
* statement type is primarily for utility operations that don't require
* capturing return values, and where the operation's side effect or
* validation is more important than its return value.
*
* Common E2E testing scenarios:
*
* - Validation assertions using TestValidator predicates (when not using
* predicate expressions)
* - Utility function calls (console.log, debugging functions)
* - Non-API side-effect operations
* - Cleanup operations that don't involve API calls
*
* **Note**: For most validation cases, prefer using predicate expressions
* (IEqualPredicate, IConditionalPredicate, etc.) instead of expression
* statements with TestValidator calls.
*
* AI function calling usage: Select when the business action's execution is
* the goal, not data capture, and when the operation is NOT an API call.
*/
export interface IExpressionStatement {
/** Type discriminator. */
type: "expressionStatement";
/**
* The expression to be executed as a statement.
*
* **Should NOT contain API function calls** - use `IApiOperateStatement`
* for those instead.
*
* Typically represents utility operations:
*
* - TestValidator function calls (though predicates are preferred)
* - Console operations for debugging
* - Non-API utility function invocations
* - Side-effect operations that don't involve the API
*
* The expression's result is discarded, making this suitable for
* void-returning operations or when return values are not needed for
* subsequent test steps.
*
* Most commonly contains ICallExpression for utility invocations.
*/
expression: IExpression;
}
/**
* Conditional statement for business rule-based test flow control.
*
* Enables test scenarios to branch based on runtime conditions or business
* rules. This should be used for genuine business logic branching where
* different test paths are needed based on data state or business
* conditions.
*
* **IMPORTANT: For validation purposes, prefer predicate expressions
* instead:**
*
* - Use `IEqualPredicate` instead of `if (x === y) throw new Error(...)`
* - Use `INotEqualPredicate` instead of `if (x !== y) throw new Error(...)`
* - Use `IConditionalPredicate` instead of `if (!condition) throw new
* Error(...)`
* - Use `IErrorPredicate` instead of `if` blocks that only contain error
* throwing
*
* **Only use IIfStatement when:**
*
* - Different business logic paths are needed (not just validation)
* - Complex conditional workflows that can't be expressed as simple predicates
* - Actor-based or feature-flag dependent test scenarios
* - Multi-step conditional operations where predicates are insufficient
*
* Business scenarios requiring conditional logic:
*
* - Actor-based test flows (premium vs regular customers)
* - Feature availability testing with different user journeys
* - Optional business process steps based on entity state
* - Complex workflow branching that involves multiple operations per branch
*
* AI function calling strategy: First consider if the validation can be
* handled by predicate expressions. Use IIfStatement only when genuine
* business logic branching is required that cannot be expressed through
* predicates.
*/
export interface IIfStatement {
/** Type discriminator. */
type: "ifStatement";
/**
* Boolean expression determining which branch to execute.
*
* Typically evaluates business conditions like user roles, feature flags,
* data states, or validation results. Should represent meaningful business
* logic rather than arbitrary technical conditions.
*
* Examples:
*
* - Customer.role === "premium"
* - Product.status === "available"
* - Order.payment_status === "completed"
*/
condition: IExpression;
/**
* Block to execute when condition is true.
*
* Contains the primary business flow for the conditional scenario. Should
* represent the main path or expected behavior when the business condition
* is met.
*/
thenStatement: IBlock;
/**
* Optional alternative block for when condition is false.
*
* Can be another IIfStatement for chained conditions (else-if) or IBlock
* for alternative business flow. May be null when no alternative action is
* needed.
*
* Business context: Represents fallback behavior, alternative user
* journeys, or error handling paths.
*/
elseStatement?: IBlock | IIfStatement | null;
}
/**
* Return statement for function termination.
*
* Rarely used in E2E test functions since they typically return void. May be
* used in helper functions or when test functions need to return specific
* data for chaining or validation purposes.
*
* **Note**: Most E2E test functions should complete naturally without
* explicit return statements, as they represent complete business workflow
* testing rather than value-returning operations.
*
* AI function calling usage: Generally avoid in main test functions. Consider
* only for special cases where test result data needs to be returned to
* calling context, such as helper functions within arrow function
* expressions.
*/
export interface IReturnStatement {
/** Type discriminator. */
type: "returnStatement";
/**
* Expression representing the value to be returned.
*
* Should evaluate to the appropriate return type expected by the function
* signature. In test contexts, typically void or validation result
* objects.
*
* Can reference previously captured data from API operations or computed
* values, but should not contain direct API calls.
*/
expression: IExpression;
}
/**
* Explicit error throwing for test failure scenarios.
*
* Used for custom error conditions or when specific business rule violations
* should cause immediate test termination with descriptive error messages.
*
* **IMPORTANT: For most validation scenarios, prefer predicate expressions:**
*
* - Use `IEqualPredicate` instead of manual equality checks with throw
* - Use `IConditionalPredicate` instead of condition checks with throw
* - Use `IErrorPredicate` for testing expected error conditions
*
* **Only use IThrowStatement when:**
*
* - Custom error handling logic that can't be expressed as predicates
* - Complex business rule violations requiring custom error messages
* - Exceptional cases where predicate expressions are insufficient
*
* E2E testing scenarios:
*
* - Custom validation failures with specific business context
* - Unexpected state conditions that should halt test execution
* - Complex error conditions requiring detailed diagnostic information
*
* AI function calling usage: Use sparingly, primarily for business logic
* violations that require explicit error reporting and cannot be handled by
* the standard predicate validation system.
*/
export interface IThrowStatement {
/** Type discriminator. */
type: "throwStatement";
/**
* Expression that evaluates to the error to be thrown.
*
* Typically an Error object construction with descriptive message
* explaining the business context of the failure. Should provide clear
* information about what business condition caused the error.
*
* Should NOT involve API calls - use IApiOperateStatement for API
* operations that are expected to throw errors, and IErrorPredicate for
* testing expected API error conditions.
*
* Example: new Error("Customer verification failed: invalid email format")
*/
expression: IExpression;
}
/* -----------------------------------------------------------
THE EXPRESSION
----------------------------------------------------------- */
/**
* Union type encompassing all possible expressions in test scenarios.
*
* Expressions represent values, computations, and operations that can be used
* within statements. This comprehensive set covers all necessary constructs
* for building complex E2E test scenarios:
*
* **Basic constructs:**
*
* - Identifiers: Variable references
* - Property/Element access: Object navigation
* - Function calls: Utility invocations (NOT API calls - use
* IApiOperateStatement)
* - Literals: Direct values
*
* **Advanced constructs:**
*
* - Random generators: Test data creation
* - Operators: Logical and arithmetic operations
* - Arrow functions: Callback definitions
* - Predicates: TestValidator validation operations (preferred over manual
* validation)
*
* **Note**: API function calls should NOT be represented as expressions. Use
* `IApiOperateStatement` for all SDK API operations instead.
*
* AI selection strategy: Choose expression type based on the specific
* operation needed in the business scenario. For API calls, always use the
* dedicated statement type rather than call expressions.
*/
export type IExpression =
// LITERALS
| IBooleanLiteral
| INumericLiteral
| IStringLiteral
| IArrayLiteralExpression
| IObjectLiteralExpression
| INullLiteral
| IUndefinedKeyword
// ACCESSORS
| IIdentifier
| IPropertyAccessExpression
| IElementAccessExpression
// OPERATORS
| ITypeOfExpression
| IPrefixUnaryExpression
| IPostfixUnaryExpression
| IBinaryExpression
// FUNCTIONAL
| IArrowFunction
| ICallExpression
| INewExpression
| IArrayFilterExpression
| IArrayForEachExpression
| IArrayMapExpression
| IArrayRepeatExpression
// RANDOM GENERATORS
| IPickRandom
| ISampleRandom
| IBooleanRandom
| IIntegerRandom
| INumberRandom
| IStringRandom
| IPatternRandom
| IFormatRandom
| IKeywordRandom
// PREDICATORS
| IEqualPredicate
| INotEqualPredicate
| IConditionalPredicate
| IErrorPredicate;
/* -----------------------------------------------------------
LITERALS
----------------------------------------------------------- */
/**
* Boolean literal for true/false values.
*
* Represents direct boolean values used in conditions, flags, and business
* rule specifications. Common in test scenarios for setting feature flags,
* validation states, and binary business decisions.
*
* E2E testing usage:
*
* - Feature flags (enabled: true/false)
* - Business state flags (active, verified, completed)
* - Validation parameters for API operations
* - Configuration options for test scenarios
*
* **Note**: Often used as arguments in `IApiOperateStatement` for boolean
* parameters, or in conditional expressions for business logic.
*/
export interface IBooleanLiteral {
/** Type discriminator. */
type: "booleanLiteral";
/**
* The boolean value (true or false).
*
* Should represent meaningful business states rather than arbitrary
* true/false values. Consider the business context when selecting the value
* based on the intended test scenario.
*/
value: boolean;
}
/**
* Numeric literal for number values.
*
* Represents direct numeric values including integers, decimals, and
* floating-point numbers. Essential for business data like quantities,
* prices, scores, and identifiers used in test scenarios.
*
* E2E testing scenarios:
*
* - Product quantities and prices for API operation parameters
* - Score values and ratings in business validations
* - Pagination parameters (page, limit) for API calls
* - Business thresholds and limits for conditional logic
* - Mathematical calculations with captured data
*
* **Note**: Commonly used as arguments in `IApiOperateStatement` for numeric
* parameters, or in comparisons with captured API response data.
*/
export interface INumericLiteral {
/** Type discriminator. */
type: "numericLiteral";
/**
* The numeric value.
*
* Can be integer or floating-point number. Should represent realistic
* business values appropriate for the test scenario context (e.g.,
* reasonable prices, quantities, scores).
*
* AI consideration: Use business-appropriate values rather than arbitrary
* numbers (e.g., 10000 for price instead of 12345.67).
*/
value: number;
}
/**
* String literal for text values.
*
* Represents direct string values including business names, descriptions,
* identifiers, and formatted data. One of the most commonly used literal
* types in E2E testing for realistic business data.
*
* E2E testing importance: Critical for providing realistic business data that
* reflects actual user input and system behavior, especially as parameters
* for API operations and in comparisons with captured response data.
*/
export interface IStringLiteral {
/** Type discriminator. */
type: "stringLiteral";
/**
* The string value.
*
* Should contain realistic business data appropriate for the context:
*
* - Names: "John Doe", "Acme Corporation"
* - Emails: "john@example.com"
* - Descriptions: "High-quality wireless headphones"
* - Codes: "PROMO2024", "SKU-12345"
* - Status values: "pending", "approved", "completed"
*
* **Usage context**: Commonly used as arguments in `IApiOperateStatement`
* for string parameters, in predicate validations for expected values, or
* in conditional expressions for business logic.
*
* AI content strategy: Use meaningful, realistic values that reflect actual
* business scenarios rather than placeholder text like "string" or "test".
*/
value: string;
}
/**
* Array literal for creating array values directly.
*
* Represents direct array construction with explicit elements. Essential for
* providing list data in test scenarios such as multiple products, user
* lists, or configuration arrays, particularly as parameters for API
* operations.
*
* E2E testing scenarios:
*
* - Product lists for bulk API operations
* - Tag arrays for categorization in API requests
* - Multiple item selections for API parameters
* - Configuration option lists for test setup
* - Multiple entity references for relationship testing
*
* **Note**: Commonly used as arguments in `IApiOperateStatement` when API
* operations require array parameters, or for constructing test data to be
* used in business logic.
*
* AI function calling usage: Use when business scenarios require explicit
* list data rather than dynamic array generation from captured API
* responses.
*/
export interface IArrayLiteralExpression {
/** Type discriminator. */
type: "arrayLiteralExpression";
/**
* Array of expressions representing the array elements.
*
* Each element can be any valid expression (literals, identifiers
* referencing captured data, function calls, etc.). Elements should
* represent meaningful business data appropriate for the array's purpose.
*
* **⚠️ CRITICAL AI RESTRICTION: Each element MUST be an AST expression, NOT
* raw JSON values! ⚠️** **❌ WRONG: ["item1", "item2", 123] (raw JSON
* values)** **✅ CORRECT: [IStringLiteral, IStringLiteral, INumericLiteral]
* (AST expressions)**
*
* Examples:
*
* - [product1, product2, product3] for entity arrays (referencing captured
* data)
* - ["electronics", "gadgets"] for category tags
* - [{ name: "file1.jpg" }, { name: "file2.jpg" }] for file lists
* - [seller.id, customer.id] for ID arrays (mixing captured data)
*
* AI content strategy: Populate with realistic business data that reflects
* actual usage patterns, mixing literals and references to captured data as
* appropriate.
*/
elements: IExpression[];
}
/**
* Object literal for creating object values directly.
*
* Represents direct object construction with explicit properties. The primary
* mechanism for creating request bodies, configuration objects, and
* structured data in E2E test scenarios, particularly as parameters for API
* operations.
*
* E2E testing importance: Critical for API request bodies in
* `IApiOperateStatement` calls and configuration objects that drive business
* operations.
*/
export interface IObjectLiteralExpression {
/** Type discriminator. */
type: "objectLiteralExpression";
/**
* Array of property assignments defining the object structure.
*
* Each property represents a key-value pair in the object. Properties
* should correspond to actual DTO structure requirements and business data
* needs when used as API request bodies.
*
* **For API operations**: Must align with API schema requirements when used
* as arguments in `IApiOperateStatement`. Property names and value types
* should match expected DTO interfaces.
*
* **For test data**: Can mix literal values with references to captured
* data from previous API operations to create realistic business
* scenarios.
*
* AI validation requirement: Ensure properties match the target schema
* definition exactly when used for API operations, including required
* fields and types.
*/
properties: IPropertyAssignment[];
}
/**
* Null literal for explicit null values.
*
* Represents explicit null values used in business scenarios where absence of
* data is meaningful. Important for optional fields, cleared states, and
* explicit "no value" conditions in API operations and business logic.
*
* E2E testing scenarios:
*
* - Optional relationship fields in API request bodies
* - Cleared user preferences in business state
* - Explicit "no selection" states for optional parameters
* - Default null values for optional business data in API operations
*
* AI decision context: Use when business logic specifically requires null
* rather than undefined or omitted properties, particularly in API request
* bodies or when comparing with captured API response data.
*/
export interface INullLiteral {
/** Type discriminator. */
type: "nullLiteral";
}
/**
* Undefined keyword for explicit undefined values.
*
* Represents explicit undefined values used when business logic requires
* undefined rather than null or omitted properties. Less commonly used than
* null in typical business scenarios, but necessary for certain API
* operations or business logic conditions.
*
* E2E testing usage:
*
* - Explicit undefined state representation in business logic
* - Clearing previously set values in test scenarios
* - API parameters that distinguish between null and undefined
* - Conditional expressions where undefined has specific meaning
*
* AI guidance: Prefer null over undefined unless specific business or API
* requirements dictate undefined usage, or when working with captured data
* that may contain undefined values.
*/
export interface IUndefinedKeyword {
/** Type discriminator. */
type: "undefinedKeyword";
}
/* -----------------------------------------------------------
ACCESSORS
----------------------------------------------------------- */
/**
* Identifier expression for referencing variables and utility functions.
*
* Represents references to previously captured variables from API operations,
* imported utility functions, or global identifiers. Essential for data flow
* in test scenarios where values from earlier API operations are used in
* later operations.
*
* **IMPORTANT**: Should NOT reference API functions directly. API operations
* should use `IApiOperateStatement` instead.
*
* **🚨 CRITICAL: SIMPLE IDENTIFIERS ONLY! 🚨**
*
* This interface is ONLY for simple identifiers (single variable names). DO
* NOT use compound expressions like:
*
* **❌ WRONG - These are NOT simple identifiers:**
*
* - `Array.isArray` (use IPropertyAccessExpression instead)
* - `user.name` (use IPropertyAccessExpression instead)
* - `items[0]` (use IElementAccessExpression instead)
* - `console.log` (use IPropertyAccessExpression instead)
* - `Math.random` (use IPropertyAccessExpression instead)
* - `x.y?.z` (use chained IPropertyAccessExpression instead)
*
* **✅ CORRECT - Simple identifiers only:**
*
* - `seller` (variable name from IApiOperateStatement)
* - `product` (variable name from IApiOperateStatement)
* - `Array` (global constructor name)
* - `console` (global object name)
* - `Math` (global object name)
*
* **For compound access, use the appropriate expression types:**
*
* - Property access: Use `IPropertyAccessExpression` (e.g., `user.name`)
* - Array/object indexing: Use `IElementAccessExpression` (e.g., `items[0]`)
* - Method calls: Use `ICallExpression` with `IPropertyAccessExpression` for
* the function
*
* Common E2E testing usage:
*
* - Referencing captured data from previous API operations
* - Referencing business entities from previous steps
* - Accessing non-API SDK utilities (simple names only)
*
* AI function calling context: Use when referencing any simple named entity
* in the test scope, excluding direct API function references which should
* use dedicated statement types. For any property access or method calls, use
* the appropriate expression types instead.
*/
export interface IIdentifier {
/** Type discriminator. */
type: "identifier";
/**
* The simple identifier name being referenced.
*
* Must be a SIMPLE identifier name (single word) that corresponds to a
* valid identifier in the current scope:
*
* - Previously captured variable names (from IApiOperateStatement
* variableName)
* - Global utility names (simple names only, not property paths)
* - Parameter names from function scope
*
* **Should NOT** reference API functions directly. Use IApiOperateStatement
* for API operations instead.
*
* **MUST NOT contain dots, brackets, or any compound access patterns.** For
* compound access, use IPropertyAccessExpression or
* IElementAccessExpression.
*
* Examples:
*
* **✅ CORRECT - Simple identifiers:**
*
* - "seller" (previously captured from API operation)
* - "product" (previously captured from API operation)
* - "Array" (global constructor, to be used with IPropertyAccessExpression
* for Array.isArray)
* - "console" (global object, to be used with IPropertyAccessExpression for
* console.log)
*
* **❌ WRONG - Compound expressions (use other expression types):**
*
* - "Array.isArray" (use IPropertyAccessExpression instead)
* - "user.name" (use IPropertyAccessExpression instead)
* - "items[0]" (use IElementAccessExpression instead)
*
* AI naming consistency: Must match exactly with variable names from
* previous IApiOperateStatement.variableName. Keep it simple - just the
* variable name, nothing more.
*/
text: string &
tags.Pattern<"^[a-zA-Z_$][a-zA-Z0-9_$]*(\.[a-zA-Z_$][a-zA-Z0-9_$]*)*$">;
}
/**
* Property access expression for object member navigation.
*
* Enables access to properties of objects, which is fundamental for
* navigating captured data from API operations, utility namespaces, and
* business entity relationships in E2E test scenarios.
*
* **IMPORTANT**: Should NOT be used to construct API function calls. Use
* `IApiOperateStatement` for all API operations instead.
*
* Critical E2E testing patterns:
*
* - Accessing properties of captured API response data (customer.id,
* order.status)
* - Extracting business data for subsequent operations
* - Optional chaining for safe property access
*
* AI function calling usage: Essential for building dot-notation chains for
* data access and utility function calls, but NOT for API operations which
* have their own dedicated statement type.
*/
export interface IPropertyAccessExpression {
/** Type discriminator. */
type: "propertyAccessExpression";
/**
* The base expression being accessed.
*
* Typically an IIdentifier for the root object, but can be another property
* access expression for chained access. Represents the object whose
* property is being accessed.
*/
expression: IExpression;
/**
* Whether to use optional chaining (?.) operator.
*
* True: Uses ?. for safe property access (property may not exist) False:
* Uses . for standard property access (property expected to exist)
*
* E2E testing context: Use optional chaining when accessing properties that
* might not exist based on business conditions or API variations.
*
* AI decision rule: Use true for optional business data, false for
* guaranteed response structures and utility function paths.
*/
questionDot?: boolean;
/**
* The property name being accessed.
*
* Must be a valid property name on the base expression's type. Should
* correspond to actual properties defined in DTO schemas or utility
* function names.
*
* AI validation requirement: Ensure property exists on the base
* expression's type according to schema definitions, excluding API paths.
*/
name: string;
}
/**
* Element access expression for dynamic property access and array indexing.
*
* Enables access to object properties using computed keys or array elements
* using indices. Useful for dynamic property access based on runtime values
* or when property names are not valid identifiers.
*
* **Primary use cases in E2E testing:**
*
* - Array element access from captured API response data (order.items[0])
* - Dynamic property access with string keys from API responses
* - Accessing properties with special characters from captured data
* - Computed property access based on test data
*
* AI function calling context: Use when property access requires computation
* or when accessing array elements by index in captured data.
*/
export interface IElementAccessExpression {
/** Type discriminator. */
type: "elementAccessExpression";
/**
* The base expression being indexed/accessed.
*
* Can be any expression that evaluates to an object or array. Typically
* represents collections or objects from captured API responses with
* dynamic properties.
*
* Should reference previously captured data from API operations rather than
* direct API calls.
*/
expression: IExpression;
/**
* Whether to use optional chaining (?.[]) operator.
*
* True: Uses ?.[] for safe element access False: Uses [] for standard
* element access
*
* Use optional chaining when the base expression might be null/undefined or
* when the accessed element might not exist in the captured data.
*/
questionDot?: boolean;
/**
* Expression that evaluates to the property key or array index.
*
* For arrays: typically INumericLiteral for index access For objects:
* typically IStringLiteral for property key Can be any expression that
* evaluates to a valid key type
*
* Examples:
*
* - INumericLiteral(0) for first array element
* - IStringLiteral("id") for property access
* - IIdentifier("index") for variable-based access
*/
argumentExpression: IExpression;
}
/* -----------------------------------------------------------
OPERATORS
----------------------------------------------------------- */
/**
* TypeOf expression for runtime type checking.
*
* Represents the JavaScript `typeof` operator for determining the type of a
* value at runtime. Essential for type validation, conditional logic based on
* data types, and ensuring captured API response data matches expected types
* in business scenarios.
*
* E2E testing scenarios:
*
* - Validating captured API response data types before use
* - Conditional business logic based on data type checking
* - Type safety verification for dynamic data from API operations
* - Ensuring proper data type handling in business workflows
*
* **Common return values:**
*
* - "string" for text data from API responses
* - "number" for numeric values from API operations
* - "boolean" for flag values from API calls
* - "object" for entity data from API responses (including arrays)
* - "undefined" for missing or uninitialized data
* - "function" for callback or utility function references
*
* AI function calling usage: Use when business logic requires runtime type
* validation of captured data or when conditional operations depend on data
* type verification from API responses.
*/
export interface ITypeOfExpression {
/** Type discriminator. */
type: "typeOfExpression";
/**
* Expression whose type should be determined at runtime.
*
* Can be any expression that evaluates to a value requiring type checking.
* Commonly used with captured data from API operations, variable
* references, or property access expressions to validate data types before
* use in business logic.
*
* Common patterns:
*
* - Identifiers referencing captured API response data
* - Property access expressions extracting fields from API responses
* - Array/object element access for nested data type validation
* - Variable references for dynamic data type checking
*
* Should reference captured data or computed values, not direct API calls.
*
* AI expression selection: Choose expressions that represent data whose
* type needs runtime verification, especially when working with dynamic API
* response data or conditional business logic.
*/
expression: IExpression;
}
/**
* Prefix unary expression for operators applied before operands.
*
* Represents unary operators that appear before their operands:
*
* - "!" for logical negation
* - "++" for pre-increment
* - "--" for pre-decrement
*
* **⚠️ IMPORTANT: For `typeof` operator, use `AutoBeTest.ITypeOfExpression`
* instead! ⚠️**
*
* If you're trying to create a `typeof X` expression, DO NOT use this
* interface with `operator: "typeof"`. Use the dedicated
* `AutoBeTest.ITypeOfExpression` interface instead, which is specifically
* designed for typeof operations.
*
* **❌ WRONG:**
*
* ```typescript
* {
* type: "prefixUnaryExpression",
* operator: "typeof", // ❌ This is incorrect!
* operand: someExpression
* }
* ```
*
* **✅ CORRECT:**
*
* ```typescript
* {
* type: "typeOfExpression", // ✅ Use this for typeof!
* expression: someExpression
* }
* ```
*
* E2E testing usage:
*
* - Logical negation for condition inversion in business logic
* - Increment/decrement for counter operations (rare in typical test scenarios)
*
* AI function calling context: Use for simple unary operations needed in
* business logic conditions or calculations involving captured test data.
*/
export interface IPrefixUnaryExpression {
/** Type discriminator. */
type: "prefixUnaryExpression";
/**
* The unary operator to apply.
*
* - "!": Logical NOT (most common in test conditions)
* - "++": Pre-increment (modify then use value)
* - "--": Pre-decrement (modify then use value)
*/
operator: "!" | "++" | "--" | "-" | "+";
/**
* The operand expression to which the operator is applied.
*
* For "!": typically boolean expressions or conditions involving captured
* data For "++/--": typically variable identifiers that need modification
*
* Should reference captured data or computed values, not direct API calls.
*/
operand: IExpression;
}
/**
* Postfix unary expression for operators applied after operands.
*
* Represents unary operators that appear after their operands:
*
* - "++" for post-increment
* - "--" for post-decrement
*
* E2E testing usage:
*
* - Counter operations where original value is used before modification
* - Loop iteration variables (though rare in typical E2E test scenarios)
*
* AI function calling context: Use when the original value is needed before
* the increment/decrement operation, typically in scenarios involving
* iteration or counting with captured test data.
*/
export interface IPostfixUnaryExpression {
/** Type discriminator. */
type: "postfixUnaryExpression";
/**
* The unary operator to apply.
*
* - "++": Post-increment (use value then modify)
* - "--": Post-decrement (use value then modify)
*/
operator: "++" | "--";
/**
* The operand expression to which the operator is applied.
*
* Typically variable identifiers that need modification. Should reference
* captured data or computed values, not direct API call results.
*/
operand: IExpression;
}
/**
* Binary expression for operations between two operands.
*
* Represents all binary operations including comparison, arithmetic, and
* logical operations. Essential for implementing business logic conditions,
* calculations, and validations in test scenarios using captured data.
*
* **🚨 CRITICAL: DO NOT confuse with property access or element access! 🚨**
*
* This interface is ONLY for binary operators (===, !==, +, -, etc.). Do NOT
* use this for:
*
* **❌ WRONG - These are NOT binary expressions:**
*
* - `Array.isArray` (use IPropertyAccessExpression instead)
* - `user.name` (use IPropertyAccessExpression instead)
* - `items[0]` (use IElementAccessExpression instead)
* - `x.y` (use IPropertyAccessExpression instead)
* - `object.property` (use IPropertyAccessExpression instead)
* - `console.log` (use IPropertyAccessExpression instead)
* - `Math.max` (use IPropertyAccessExpression instead)
* - `array.length` (use IPropertyAccessExpression instead)
* - `string.includes` (use IPropertyAccessExpression instead)
*
* **✅ CORRECT - Binary expressions only:**
*
* - `x === y` (equality comparison)
* - `a + b` (arithmetic operation)
* - `count > 0` (comparison operation)
* - `isActive && isValid` (logical operation)
*
* **For property/method access, use the appropriate expression types:**
*
* - Property access: Use `IPropertyAccessExpression` (e.g., `user.name`,
* `Array.isArray`, `array.length`)
* - Array/object indexing: Use `IElementAccessExpression` (e.g., `items[0]`,
* `obj["key"]`)
* - Method calls: Use `ICallExpression` with `IPropertyAccessExpression` for
* the function
*
* **Common AI mistakes to avoid:**
*
* - Using IBinaryExpression for dot notation (`.`) - this is property access,
* not a binary operator
* - Using IBinaryExpression for `.length`, `.includes()`, etc. - these are
* property/method access
* - Confusing property access with binary operations
* - Mixing structural navigation with computational operations
*
* E2E testing importance: Critical for implementing business rule
* validations, data comparisons, and conditional logic that reflects
* real-world application behavior using data captured from API responses.
*/
export interface IBinaryExpression {
/** Type discriminator. */
type: "binaryExpression";
/**
* Left operand of the binary operation.
*
* Typically represents the primary value being compared or operated upon.
* In business contexts, often represents actual values from captured API
* responses or business entities from previous operations.
*
* **Note**: If you need to access object properties (like `user.name`,
* `array.length`), use IPropertyAccessExpression as the left operand, not
* IBinaryExpression.
*/
left: IExpression;
/**
* Binary operator defining the operation type.
*
* **⚠️ IMPORTANT: These are computational/logical operators ONLY! ⚠️**
*
* **🚨 CRITICAL JavaScript Requirements: 🚨**
*
* **❌ NEVER use loose equality operators:**
*
* - `==` (loose equality) - This is NOT supported and causes type coercion
* bugs
* - `!=` (loose inequality) - This is NOT supported and causes type coercion
* bugs
*
* **✅ ALWAYS use strict equality operators:**
*
* - `===` (strict equality) - Use this for all equality comparisons
* - `!==` (strict inequality) - Use this for all inequality comparisons
*
* **Why strict equality is required:**
*
* - Prevents unexpected type coercion (e.g., `"0" == 0` is true, but `"0" ===
* 0` is false)
* - Ensures predictable behavior in business logic
* - Follows TypeScript and modern JavaScript best practices
* - Avoids subtle bugs in API response validation
*
* Do NOT include:
*
* - `.` (dot) - This is property access, use IPropertyAccessExpression
* - `[]` (brackets) - This is element access, use IElementAccessExpression
* - `()` (parentheses) - This is function call, use ICallExpression
* - `.length`, `.includes`, etc. - These are property/method access, use
* IPropertyAccessExpression
* - '.length ===': Capsule left expression into IPropertyAccessExpression
* - '[0] >=' Capsule left expression into IElementAccessExpression
*
* **Comparison operators:**
*
* - "===", "!==": Strict equality/inequality (REQUIRED - never use == or !=)
* - "<", "<=", ">", ">=": Numerical/string comparisons
*
* **Arithmetic operators:**
*
* - "+", "-", "*", "/", "%": Mathematical operations
*
* **Logical operators:**
*
* - "&&": Logical AND (both conditions must be true)
* - "||": Logical OR (either condition can be true)
*
* AI selection guide:
*
* - Use === for equality checks (NEVER ==)
* - Use !== for inequality checks (NEVER !=)
* - Use logical operators for combining business conditions
* - Use arithmetic for calculations on captured data
* - For property access, method calls, or array indexing, use the appropriate
* expression types instead
*/
operator:
| "==="
| "!=="
| "<"
| "<="
| ">"
| ">="
| "+"
| "-"
| "*"
| "/"
| "%"
| "&&"
| "||"
| "instanceof";
/**
* Right operand of the binary operation.
*
* Represents the comparison value, second operand in calculations, or
* second condition in logical operations. In business contexts, often
* represents expected values, business rule thresholds, or additional
* captured data from API responses.
*
* **Note**: If you need to access object properties (like `order.status`,
* `items.length`), use IPropertyAccessExpression as the right operand, not
* IBinaryExpression.
*/
right: IExpression;
}
/**
* Conditional expression for inline value selection.
*
* Represents the ternary operator (condition ? trueValue : falseValue) for
* inline conditional value selection. Useful when values need to be chosen
* based on business conditions within expressions.
*
* E2E testing scenarios:
*
* - Conditional parameter values based on captured test data
* - Dynamic value selection based on business rules from API responses
* - Fallback value specification for optional data
* - Simple conditional logic within expression contexts
*
* AI function calling context: Use when business logic requires different
* values based on runtime conditions within expressions, where the conditions
* and values don't involve direct API calls.
*/
export interface IConditionalExpression {
/** Type discriminator. */
type: "conditionalExpression";
/**
* Boolean condition determining which value to select.
*
* Should represent meaningful business logic conditions based on captured
* data rather than arbitrary technical conditions. Can reference data
* captured from previous API operations.
*/
condition: IExpression;
/**
* Expression evaluated and returned when condition is true.
*
* Represents the primary or expected value for the business scenario. Can
* reference captured API data or computed values.
*/
whenTrue: IExpression;
/**
* Expression evaluated and returned when condition is false.
*
* Represents the alternative or fallback value for the business scenario.
* Can reference captured API data or computed values.
*/
whenFalse: IExpression;
}
/* -----------------------------------------------------------
FUNCTIONAL
----------------------------------------------------------- */
/**
* Arrow function expression for callback definitions.
*
* Used primarily for callback functions required by certain utility functions
* or specialized operations. In E2E testing, commonly needed for array
* operations, error handling callbacks, or random data generation functions.
*
* E2E testing scenarios:
*
* - Callback functions for IErrorPredicate (testing expected API errors)
* - Generator functions for IArrayRepeatExpression (creating test data arrays)
* - Filter/transform functions for captured data manipulation
* - Event handler functions for specialized testing scenarios
*
* AI function calling usage: Generate when utility operations require
* function parameters or when data transformation callbacks are needed within
* the test flow.
*/
export interface IArrowFunction {
/** Type discriminator. */
type: "arrowFunction";
/**
* The function body containing the function's logic.
*
* Contains the statements that comprise the function's implementation. In
* test contexts, typically contains simple operations like data
* transformation, validation, or utility calls.
*
* Can include IApiOperateStatement for API operations within the callback,
* though this should be used judiciously and only when the callback
* specifically requires API interactions.
*
* Should represent meaningful business logic rather than arbitrary
* computational operations.
*/
body: IBlock;
}
/**
* Function call expression for non-API function invocations and utility
* calls.
*
* **IMPORTANT: For API function calls, use `IApiOperateStatement` instead.**
* This type should only be used for:
*
* - Helper functions and transformations
* - Built-in JavaScript functions
* - Non-API library function calls
*
* Essential for E2E testing for utility operations, but API calls should use
* the dedicated `IApiOperateStatement` for proper handling of business
* operations and response capturing.
*
* AI function calling importance: This represents utility and validation
* operations in test scenarios, but should NOT be used for SDK API calls
* which have their own dedicated statement type.
*/
export interface ICallExpression {
/** Type discriminator. */
type: "callExpression";
/**
* Expression representing the function to be called.
*
* **Should NOT represent API/SDK functions** - use `IApiOperateStatement`
* for those instead.
*
* Typically represents utility functions:
*
* - Built-in functions (Array.from, Object.keys, etc.)
* - Helper/transformation functions
*
* Can also be a simple identifier for direct function references.
*
* AI requirement: Must NOT resolve to SDK API functions. Those should use
* the dedicated API function call statement type.
*/
expression: IExpression;
/**
* Array of argument expressions passed to the function.
*
* Each argument must match the expected parameter type of the called
* function. Order and types must correspond exactly to the function
* signature defined in utility or validation documentation.
*
* Common patterns:
*
* - Transformation parameters for utility functions
*
* AI validation: Ensure argument types and count match the target
* function's signature exactly, excluding API functions.
*/
arguments: IExpression[];
}
/**
* New expression for object instantiation.
*
* Creates new instances of objects, primarily used for:
*
* - Error object creation for throw statements
* - Date object creation for timestamp values
* - Custom object instantiation when required by utility functions
*
* E2E testing context: Most commonly used for creating Error objects in throw
* statements or Date objects for time-sensitive test data. Also used for
* instantiating utility objects that don't involve API calls.
*
* AI function calling usage: Use when business logic requires explicit object
* instantiation rather than literal values, excluding API-related entity
* creation.
*/
export interface INewExpression {
/** Type discriminator. */
type: "newExpression";
/**
* Expression representing the constructor function.
*
* Typically an identifier for built-in constructors:
*
* - "Error" for error objects
* - "Date" for date objects
* - Custom class identifiers when needed for utility purposes
*
* Should NOT represent API-related constructors or entity builders.
*/
expression: IExpression;
/**
* Arguments passed to the constructor.
*
* Must match the constructor's parameter signature. For Error objects:
* typically string message For Date objects: typically string or number
* timestamp For other constructors: appropriate parameter types
*
* Arguments should be derived from captured data, literals, or
* computations, not from direct API calls.
*/
arguments: IExpression[];
}
/**
* Array filter expression for selecting elements that meet criteria.
*
* Filters array elements based on a predicate function, keeping only elements
* that satisfy the specified condition. Essential for extracting subsets of
* business data from captured API responses or test collections based on
* business rules and conditions.
*
* E2E testing scenarios:
*
* - Filtering products by category or price range from API response arrays
* - Selecting active users from captured user lists for business operations
* - Finding orders with specific status from API response collections
* - Extracting eligible items for business rule validation
*
* **Primary usage**: Processing captured data from API operations to create
* focused datasets for subsequent operations or validations.
*
* AI function calling strategy: Use when business logic requires working with
* specific subsets of data captured from API responses, especially for
* conditional operations or validation scenarios.
*/
export interface IArrayFilterExpression {
/** Type discriminator. */
type: "arrayFilterExpression";
/**
* Array expression to be filtered.
*
* Must be an expression that evaluates to an array containing business
* entities or data that requires filtering based on specific criteria. Can
* reference variables from previous API calls, array literals, or other
* expressions that produce arrays.
*
* The array elements will be individually evaluated by the filter function
* to determine inclusion in the filtered result. Each element should be
* compatible with the filtering logic defined in the function parameter.
*
* Examples:
*
* - Reference to captured product array from API response
* - Array of user entities from previous API operations
* - Collection of business data requiring conditional processing
* - Variable references to previously constructed arrays
*
* Business context: Typically represents collections of entities that need
* subset selection based on business rules, such as active users, available
* products, or eligible transactions.
*/
array: IExpression;
/**
* Arrow function defining the filter criteria.
*
* Called for each array element to determine if it should be included in
* the filtered result. Should return a boolean expression that evaluates
* business conditions relevant to the filtering purpose.
*
* The function parameter represents the current array element being
* evaluated and can be used to access properties for business logic
* conditions.
*/
function: IArrowFunction;
}
/**
* Array forEach expression for iterating over elements with side effects.
*
* Executes a function for each array element without returning a new array.
* Used for performing operations on each element such as validation, logging,
* or side-effect operations that don't require collecting results.
*
* E2E testing scenarios:
*
* - Validating each product in a collection meets business requirements
* - Logging details of each order for debugging test scenarios
* - Performing individual validations on user entities from API responses
* - Executing side-effect operations on captured business data
*
* **Note**: Use when you need to process each element but don't need to
* transform or collect results. For transformations, use
* IArrayMapExpression.
*
* AI function calling strategy: Use for validation operations or side effects
* on each element of captured data collections, especially when the operation
* doesn't produce a new collection.
*/
export interface IArrayForEachExpression {
/** Type discriminator. */
type: "arrayForEachExpression";
/**
* Array expression to iterate over.
*
* Must be an expression that evaluates to an array containing business
* entities or data that requires individual element processing. Often
* references collections captured from API operations or constructed arrays
* for testing.
*
* Each element in the array will be passed to the function for processing.
* The array can contain any type of business data appropriate for the
* intended operation.
*
* Examples:
*
* - Array of customers from API response requiring individual validation
* - Collection of orders needing status verification
* - List of products requiring individual business rule checks
* - User entities from previous API calls needing processing
*
* Business context: Represents collections where each element needs
* individual attention, such as validation, logging, or side-effect
* operations that don't transform the data but perform actions based on
* each element's properties.
*/
array: IExpression;
/**
* Arrow function executed for each array element.
*
* Called once for each element in the array. Should contain operations that
* process the individual element, such as validation calls, logging
* operations, or other side effects relevant to the business scenario.
*
* The function parameter represents the current array element and can be
* used to access properties and perform element-specific operations.
*/
function: IArrowFunction;
}
/**
* Array map expression for transforming elements into new values.
*
* Transforms each array element using a function, producing a new array with
* the transformed values. Essential for data transformation, extraction of
* specific properties, and converting between data formats in business
* scenarios.
*
* E2E testing scenarios:
*
* - Extracting IDs from captured entity arrays for subsequent API operations
* - Transforming product data for different API request formats
* - Converting user objects to summary data for business validations
* - Creating parameter arrays from captured business entities
*
* **Primary usage**: Data transformation when you need to convert captured
* API response data into formats suitable for subsequent operations or when
* extracting specific information from business entities.
*
* AI function calling strategy: Use when business logic requires transforming
* collections of captured data into different formats, especially for
* preparing data for subsequent API operations.
*/
export interface IArrayMapExpression {
/** Type discriminator. */
type: "arrayMapExpression";
/**
* Array expression to be transformed.
*
* Must be an expression that evaluates to an array containing business
* entities or data that needs transformation. Often references collections
* captured from API operations that require conversion to different
* formats.
*
* Each element in the array will be passed to the transformation function
* to produce a corresponding element in the resulting array. The original
* array remains unchanged.
*
* Examples:
*
* - Array of product entities requiring ID extraction
* - Collection of users needing transformation to summary format
* - Business data requiring format conversion for API parameters
* - Entity arrays from API responses needing property extraction
*
* Business context: Represents source data that needs to be converted to a
* different format or structure, such as extracting specific fields,
* calculating derived values, or preparing data for subsequent API
* operations.
*/
array: IExpression;
/**
* Arrow function defining the transformation logic.
*
* Called for each array element to produce the transformed value. Should
* return an expression that represents the desired transformation of the
* input element, creating business-appropriate output data.
*
* The function parameter represents the current array element being
* transformed and can be used to access properties and create the
* transformed result.
*/
function: IArrowFunction;
}
/**
* Array repeat generator for dynamic test data creation.
*
* Generates arrays with specified length by repeating a generator function.
* Essential for creating realistic test data that simulates collections like
* product lists, user arrays, or transaction histories for use in API
* operations.
*
* **Primary usage**: Creating dynamic test data for API operation parameters
* that require arrays, or for generating test scenarios with specific data
* sizes.
*
* E2E testing importance: Enables testing with realistic data volumes and
* variations that reflect real-world usage patterns, particularly when
* combined with `IApiOperateStatement` for bulk operations.
*
* AI function calling strategy: Use when business scenarios require
* collections of specific size rather than fixed arrays, especially for API
* operations that handle multiple entities.
*/
export interface IArrayRepeatExpression {
/** Type discriminator. */
type: "arrayRepeatExpression";
/**
* Expression determining how many elements to generate.
*
* Must be an expression that evaluates to a number representing the desired
* array length. Can be a literal number for fixed length or a random
* generator for variable length. Should reflect realistic business
* constraints and use cases.
*
* **⚠️ CRITICAL AI RESTRICTION: This MUST be an AST expression, NOT a raw
* number! ⚠️**
*
* **❌ WRONG: 5 (raw number)** **✅ CORRECT: INumericLiteral with value: 5
* (AST expression)** **✅ CORRECT: IIntegerRandom for variable length (AST
* expression)**
*
* Examples:
*
* - `INumericLiteral(5)` for exactly 5 elements
* - `IIntegerRandom({ minimum: 3, maximum: 7 })` for variable length
* - `IIdentifier("itemCount")` for dynamic count from captured data
*
* Business considerations:
*
* - 1-10 for shopping cart items (realistic user behavior)
* - 5-20 for product reviews (typical engagement levels)
* - 10-100 for product catalogs (reasonable inventory sizes)
* - 3-8 for team member lists (typical business team sizes)
*
* The count should be appropriate for the business context and reflect
* realistic data volumes that would be encountered in actual API
* operations.
*
* AI constraint setting: Choose counts that make business sense for the
* specific use case, considering both realistic data volumes and system
* performance implications when used in API operations.
*/
count: IExpression;
/**
* Arrow function for generating individual array elements.
*
* Called once for each array element to generate the element value. Should
* produce business-appropriate data for the array's purpose.
*
* The function typically uses random generators to create varied but
* realistic business entities. Can also reference captured data from
* previous API operations to create related test data.
*
* AI implementation requirement: Generate meaningful business data rather
* than arbitrary random values. Consider how the generated data will be
* used in subsequent API operations.
*/
function: IArrowFunction;
}
/* -----------------------------------------------------------
RANDOM
----------------------------------------------------------- */
/**
* Randomly selects an element from an array expression.
*
* Picks one element randomly from the provided array expression. Used for
* selecting categories, status values, etc. for API parameters and test
* data.
*/
export interface IPickRandom {
/** Type discriminator */
type: "pickRandom";
/**
* Array expression to pick from.
*
* Must be an expression that evaluates to an array containing the candidate
* elements for random selection. Can be any expression type that produces
* an array:
*
* - Array literals with explicit elements
* - Variable references to previously captured arrays
* - Function calls that return arrays
* - Property access to array properties
*
* The array should contain at least one element for meaningful random
* selection. All elements should be of compatible types appropriate for the
* business context.
*
* Example:
*
* ```typescript
* {
* "type": "pickRandom",
* "array": {
* "type": "arrayLiteralExpression",
* "elements": [
* { "type": "stringLiteral", "value": "electronics" },
* { "type": "stringLiteral", "value": "clothing" },
* { "type": "stringLiteral", "value": "books" }
* ]
* }
* }
* ```
*
* Business usage: Commonly used for selecting random categories, status
* values, or options in API operation parameters to create varied test
* scenarios.
*/
array: IExpression;
}
/**
* Random sampler for selecting multiple items from a collection.
*
* Randomly selects a specified number of elements from a provided collection
* without duplication. Useful for creating realistic subsets of business data
* like featured products, selected users, or sample transactions for API
* operations.
*
* E2E testing scenarios:
*
* - Selecting featured products from catalog for API parameters
* - Choosing random users for notification API calls
* - Sampling transactions for analysis operations
* - Creating test data subsets for bulk API operations
*
* **Usage with APIs**: Often combined with `IApiOperateStatement` to perform
* operations on multiple randomly selected entities.
*
* AI function calling context: Use when business scenarios require multiple
* selections from a larger set without duplication, particularly for API
* operations that handle multiple entities.
*/
export interface ISampleRandom {
/** Type discriminator. */
type: "sampleRandom";
/**
* Array expression containing the collection to sample from.
*
* Must be an expression that evaluates to an array containing more elements
* than the requested sample count to enable meaningful random selection.
* Elements should be valid business entities appropriate for the sampling
* context.
*
* Can reference captured data from previous API operations, array literals,
* or other expressions that produce collections suitable for sampling.
*
* Examples:
*
* - Array of product IDs from captured API response
* - Collection of user entities from previous API call
* - Available options from business configuration
* - Variable references to previously constructed arrays
*
* The collection size should exceed the `count` parameter to ensure
* meaningful random sampling without duplication.
*
* Business context: Typically represents pools of available entities like
* product catalogs, user lists, or option sets that need subset selection
* for API operations.
*/
array: IExpression;
/**
* Expression determining how many elements to select from the collection.
*
* Must be an expression that evaluates to a number representing the desired
* sample size. Should be less than or equal to the collection size to avoid
* sampling errors. Should represent realistic business requirements for the
* sampling scenario.
*
* **⚠️ CRITICAL AI RESTRICTION: This MUST be an AST expression, NOT a raw
* number! ⚠️**
*
* **❌ WRONG: 3 (raw number)** **✅ CORRECT: INumericLiteral with value: 3
* (AST expression)** **✅ CORRECT: IIntegerRandom for variable count (AST
* expression)**
*
* Examples:
*
* - `INumericLiteral(3)` for exactly 3 featured products
* - `IIntegerRandom({ minimum: 2, maximum: 5 })` for variable selection
* - `IIdentifier("sampleSize")` for dynamic count from captured data
*
* Business considerations:
*
* - 3-5 for featured products (typical homepage display)
* - 5-10 for sample users (reasonable notification batch)
* - 10-20 for transaction samples (meaningful analysis size)
* - 2-8 for recommended items (typical recommendation count)
*
* The count should be appropriate for the business context and not exceed
* the available collection size. Consider both user experience and system
* performance when selecting sample sizes for API operations.
*
* AI selection strategy: Choose counts that reflect realistic business
* requirements and typical usage patterns, especially when the sampled data
* will be used in subsequent API operations.
*/
count: IExpression;
}
/**
* Random boolean generator for true/false values with probability control.
*
* Generates boolean values with optional probability weighting. Useful for
* simulating business scenarios with probabilistic outcomes like feature
* flags, user preferences, or conditional states in API operations.
*
* E2E testing scenarios:
*
* - Random feature flag states for API parameter variation
* - User preference simulation in test data
* - Conditional business logic testing with probabilistic outcomes
* - Random yes/no decisions for API operation parameters
*
* **API usage**: Commonly used as boolean parameters in
* `IApiOperateStatement` to create varied test scenarios with realistic
* probability distributions.
*
* AI function calling usage: Use when business logic involves probabilistic
* boolean outcomes rather than deterministic values, especially for creating
* diverse API operation parameters.
*/
export interface IBooleanRandom {
/** Type discriminator. */
type: "booleanRandom";
/**
* Probability of generating true (0.0 to 1.0).
*
* - Null: 50/50 probability (default random boolean)
* - 0.0: Always false
* - 1.0: Always true
* - 0.7: 70% chance of true, 30% chance of false
*
* Should reflect realistic business probabilities:
*
* - High probability (0.8-0.9) for common positive states
* - Low probability (0.1-0.2) for rare conditions
* - Default (null) for balanced scenarios
*
* AI probability selection: Choose based on real-world business likelihood
* of the condition being true, especially when used in API operations.
*/
probability?: number | null;
}
/**
* Random integer generator with business-appropriate constraints.
*
* Generates random integer values within specified ranges and constraints.
* Essential for creating realistic business numeric data like quantities,
* counts, scores, and identifiers for use in API operations and business
* logic.
*
* E2E testing importance: Provides realistic numeric data that reflects
* actual business value ranges and constraints, particularly for API
* operation parameters and validation scenarios.
*/
export interface IIntegerRandom {
/** Type discriminator. */
type: "integerRandom";
/**
* Minimum value (inclusive).
*
* - Null: No minimum constraint
* - Number: Specific minimum value
*
* Should reflect business constraints:
*
* - 0 for non-negative quantities
* - 1 for positive-only values
* - Business-specific minimums for scores, ratings, etc.
*
* AI constraint setting: Choose minimums that make business sense for the
* specific data type being generated, especially when used in API
* operations.
*/
minimum?: (number & tags.Type<"int32">) | null;
/**
* Maximum value (inclusive).
*
* - Null: No maximum constraint
* - Number: Specific maximum value
*
* Should reflect realistic business limits:
*
* - 100 for percentage values
* - 5 for rating scales
* - Reasonable inventory quantities for business operations
* - Business-specific maximums that align with API constraints
*
* AI constraint setting: Choose maximums that reflect real-world business
* limits and system constraints, particularly for API operation
* parameters.
*/
maximum?: (number & tags.Type<"int32">) | null;
/**
* Multiple constraint for generated values.
*
* - Null: No multiple constraint
* - Number: Generated value must be multiple of this number
*
* Business use cases:
*
* - 5 for rating systems (0, 5, 10, 15, ...)
* - 10 for price increments in business systems
* - Custom business increment requirements for API parameters
*
* AI usage: Apply when business rules require specific value increments,
* especially for API operations with constrained parameter values.
*/
multipleOf?: (number & tags.Type<"int32">) | null;
}
/**
* Random number generator for decimal/floating-point values.
*
* Generates random decimal values within specified ranges and constraints.
* Essential for business data like prices, percentages, measurements, and
* calculated values used in API operations and business validations.
*
* E2E testing scenarios:
*
* - Product prices and costs for API operation parameters
* - Percentage values and rates for business calculations
* - Measurement data for physical product specifications
* - Financial calculations and monetary values
* - Performance metrics and business KPIs
*/
export interface INumberRandom {
/** Type discriminator. */
type: "numberRandom";
/**
* Minimum value (inclusive).
*
* - Null: No minimum constraint
* - Number: Specific minimum value (can be decimal)
*
* Business considerations:
*
* - 0.0 for non-negative amounts
* - 0.01 for minimum price values in business systems
* - Business-specific decimal minimums for API constraints
*
* AI constraint setting: Consider business rules for minimum values,
* especially for monetary and measurement data used in API operations.
*/
minimum?: number | null;
/**
* Maximum value (inclusive).
*
* - Null: No maximum constraint
* - Number: Specific maximum value (can be decimal)
*
* Business considerations:
*
* - 100.0 for percentage values
* - Realistic price ranges for products in API operations
* - System limits for calculations and business rules
*
* AI constraint setting: Set realistic upper bounds based on business
* context and system capabilities, especially for API parameter
* validation.
*/
maximum?: number | null;
/**
* Multiple constraint for decimal precision.
*
* - Null: No multiple constraint
* - Number: Generated value must be multiple of this number
*
* Business use cases:
*
* - 0.01 for currency precision (cents) in financial API operations
* - 0.5 for half-point rating systems
* - Custom precision requirements for business calculations
*
* AI precision consideration: Match business precision requirements for the
* specific data type (currency, measurements, etc.) and API constraints.
*/
multipleOf?: number | null;
}
/**
* Random string generator with length constraints.
*
* Generates random strings within specified length ranges. Useful for
* creating variable-length text data like names, descriptions, codes, and
* identifiers for use in API operations and business logic testing.
*
* E2E testing scenarios:
*
* - User names and nicknames for API operation parameters
* - Product descriptions and content for API requests
* - Generated codes and tokens for business operations
* - Text content of varying lengths for validation testing
* - Custom identifiers for business entity creation
*
* **API usage**: Commonly used to generate string parameters for
* `IApiOperateStatement` calls with appropriate length constraints.
*/
export interface IStringRandom {
/** Type discriminator. */
type: "stringRandom";
/**
* Minimum string length.
*
* - Null: No minimum length constraint
* - Number: Minimum number of characters
*
* Business considerations:
*
* - 3 for minimum usernames in business systems
* - 8 for minimum passwords for security requirements
* - 1 for required non-empty fields in API operations
* - Business-specific minimum requirements for validation
*
* AI length setting: Consider business validation rules and user experience
* requirements for minimum lengths, especially for API parameter
* constraints.
*/
minLength?: (number & tags.Type<"uint32">) | null;
/**
* Maximum string length.
*
* - Null: No maximum length constraint
* - Number: Maximum number of characters
*
* Business considerations:
*
* - 255 for typical database field limits
* - 50 for names and titles in business systems
* - 1000 for descriptions and content fields
* - System-specific character limits for API operations
*
* AI length setting: Respect database constraints and UI limitations while
* allowing realistic content length variation for API operations.
*/
maxLength?: (number & tags.Type<"uint32">) | null;
}
/**
* Pattern-based random string generator.
*
* Generates strings matching specific patterns using regular expressions or
* format strings. Essential for creating data that matches exact business
* format requirements like codes, identifiers, and structured text for API
* operations.
*
* E2E testing scenarios:
*
* - Product SKU generation for API parameters
* - User ID formats for business system integration
* - Business code patterns for API operations
* - Structured identifier creation for entity relationships
* - Format-specific text generation for validation testing
*
* **API integration**: Particularly useful for generating parameters that
* must match specific format requirements in `IApiOperateStatement` calls.
*
* AI pattern usage: Ensure patterns match actual business format requirements
* and API validation rules.
*/
export interface IPatternRandom {
/** Type discriminator. */
type: "patternRandom";
/**
* Regular expression pattern for string generation.
*
* Defines the exact format structure for generated strings. Should match
* business format requirements and validation patterns used in API
* operations.
*
* Examples:
*
* - "SKU-[0-9]{6}" for product SKUs in business systems
* - "[A-Z]{3}-[0-9]{4}" for order codes in API operations
* - "[a-zA-Z]{5,10}" for username patterns with length constraints
* - "[A-Z]{2}[0-9]{8}" for business reference numbers
*
* AI pattern creation: Ensure patterns generate valid data that passes
* business validation rules and format requirements used in API calls.
*/
pattern: string;
}
/**
* Format-based random data generator.
*
* Generates data matching specific standardized formats like emails, UUIDs,
* dates, and URLs. Critical for creating valid business data that conforms to
* standard formats and validation requirements in API operations.
*
* E2E testing importance: Ensures generated data passes format validation and
* represents realistic business data types, particularly essential for API
* operation parameters that require specific formats.
*/
export interface IFormatRandom {
/** Type discriminator. */
type: "formatRandom";
/**
* Standardized format specification for data generation.
*
* Supports common business data formats essential for API operations:
*
* **Security & Encoding:**
*
* - "binary": Binary data representation
* - "byte": Base64 encoded data
* - "password": Password strings for authentication
* - "regex": Regular expression patterns
*
* **Identifiers:**
*
* - "uuid": Universally unique identifiers for entity references
*
* **Network & Communication:**
*
* - "email": Email addresses for user-related API operations
* - "hostname": Network hostnames for system integration
* - "idn-email": Internationalized email addresses
* - "idn-hostname": Internationalized hostnames
* - "ipv4": IPv4 addresses for network configuration
* - "ipv6": IPv6 addresses for network configuration
*
* **Web & URI:**
*
* - "uri": Uniform Resource Identifiers for API endpoints
* - "iri": Internationalized Resource Identifiers
* - "iri-reference": IRI references
* - "uri-reference": URI references
* - "uri-template": URI templates
* - "url": Web URLs for external resource references
*
* **Date & Time:**
*
* - "date-time": ISO 8601 date-time strings for API timestamps
* - "date": Date-only strings for business date fields
* - "time": Time-only strings for scheduling operations
* - "duration": Time duration strings for business processes
*
* **JSON & Pointers:**
*
* - "json-pointer": JSON Pointer strings for data navigation
* - "relative-json-pointer": Relative JSON Pointers
*
* AI format selection: Choose formats that match the business context and
* validation requirements of the target API operation field.
*/
format:
| "binary"
| "byte"
| "password"
| "regex"
| "uuid"
| "email"
| "hostname"
| "idn-email"
| "idn-hostname"
| "iri"
| "iri-reference"
| "ipv4"
| "ipv6"
| "uri"
| "uri-reference"
| "uri-template"
| "url"
| "date-time"
| "date"
| "time"
| "duration"
| "json-pointer"
| "relative-json-pointer";
}
/**
* Domain-specific random data generator.
*
* Generates realistic business data for specific domains using predefined
* generation rules. Provides contextually appropriate data that reflects
* real-world business scenarios and user behavior for API operations.
*
* E2E testing importance: Creates realistic test data that closely mimics
* actual user input and business content, improving test scenario
* authenticity and catching real-world edge cases in API operations.
*/
export interface IKeywordRandom {
/** Type discriminator. */
type: "keywordRandom";
/**
* Domain-specific data generation keyword.
*
* **🚨 CRITICAL: ONLY use the exact predefined constant values! 🚨**
*
* **❌ UNSUPPORTED values that will cause errors:**
*
* - "title", "comment", "article", "description", "text", "body"
* - "summary", "details", "note", "message", "subject", "sentence"
* - "address", "phone", "email", "url", "username"
* - Any value not explicitly listed in the supported constants below
*
* **✅ SUPPORTED constant values ONLY:**
*
* **Text & Content:**
*
* - "alphabets": Random alphabetic strings for codes and identifiers
* - "alphaNumeric": Random alphanumeric strings for mixed-format identifiers
* - "paragraph": Realistic paragraph text for content fields
* - "content": Generic content text for description fields
*
* **Personal Information:**
*
* - "mobile": Mobile phone numbers for contact information in APIs
* - "name": Personal names (first, last, full) for user-related operations
*
* **🎯 AI SELECTION STRATEGY: Map your needs to existing constants!**
*
* Before trying unsupported values, find the closest match from available
* options:
*
* - **Need titles/headers?** → Use "content" (generic text content)
* - **Need comments/descriptions?** → Use "paragraph" (realistic paragraph
* text)
* - **Need articles/body text?** → Use "paragraph" (longer text content)
* - **Need details/summaries?** → Use "content" (general text fields)
* - **Need phone numbers?** → Use "mobile" (phone number format)
* - **Need usernames/IDs?** → Use "alphaNumeric" (mixed identifier format)
* - **Need codes/tokens?** → Use "alphabets" (alphabetic strings)
*
* **Usage strategy for API operations:**
*
* - Use "name" for user registration and profile API calls
* - Use "mobile" for contact information in business APIs
* - Use "paragraph" for descriptions, comments, articles, and content in API
* requests
* - Use "content" for general text fields, titles, subjects in API parameters
* - Use "alphabets"/"alphaNumeric" for codes, usernames, and identifiers in
* API calls
*
* **⚠️ REMINDER: The system only supports these 6 exact constants. No
* exceptions!** If you need functionality not covered by these constants,
* use other generators like:
*
* - IStringRandom for custom length text
* - IFormatRandom for specific formats (email, url, etc.)
* - IPatternRandom for custom patterns
*/
keyword:
| "alphabets"
| "alphaNumeric"
| "paragraph"
| "content"
| "mobile"
| "name";
}
/**
* Equality validation predicate for TestValidator assertion.
*
* Generates TestValidator.equals() calls to verify that two values are equal.
* This is the most commonly used validation pattern in E2E tests for
* confirming API responses match expected values and ensuring data integrity
* throughout business workflows.
*
* **Preferred over manual validation**: Use this instead of `IIfStatement`
* with throw statements for equality checking.
*
* E2E testing scenarios:
*
* - Verifying API response data matches expected values
* - Confirming entity IDs are correctly preserved across API operations
* - Validating state transitions in business workflows
* - Ensuring data consistency after CRUD operations via API calls
*
* AI function calling usage: Use after API operations (IApiOperateStatement)
* to validate response data and confirm business logic execution. Essential
* for maintaining test reliability and catching regressions.
*/
export interface IEqualPredicate {
/** Type discriminator. */
type: "equalPredicate";
/**
* Descriptive title explaining what is being validated.
*
* 🚨 CRITICAL: This MUST be a simple string value, NOT an expression! 🚨
*
* ❌ WRONG - DO NOT use expressions of any kind:
*
* - { type: "binaryExpression", operator: "+", left: "Customer", right: "
* validation" }
* - { type: "stringLiteral", value: "some string" }
* - Any IExpression types - this is NOT an expression field!
*
* ✅ CORRECT - Use direct string values only:
*
* - "Customer ID should match created entity"
* - Simple, complete descriptive text as a raw string
*
* Should clearly describe the business context and expectation being
* tested. This title appears in test failure messages to help with
* debugging.
*
* Examples:
*
* - "Customer ID should match created entity"
* - "Order status should be confirmed after payment"
* - "Product price should equal the specified amount"
* - "Review content should match updated values"
*
* AI title strategy: Use business-meaningful descriptions that explain the
* validation purpose and help developers understand test failures.
*/
title: string & tags.MinLength<1>;
/**
* Expected value expression (first parameter to TestValidator.equals).
*
* Represents the value that should be returned or the expected state after
* a business operation. Typically literal values or previously captured
* data from earlier API operations.
*
* Common patterns:
*
* - String literals for expected names, statuses, or codes
* - Numeric literals for expected quantities, prices, or scores
* - Identifiers referencing captured entity IDs or data from API operations
* - Object literals for expected data structures
*
* AI value selection: Choose expected values that reflect realistic
* business outcomes and match the API response schema.
*/
x: IExpression;
/**
* Actual value expression (second parameter to TestValidator.equals).
*
* Represents the actual value returned from API operations or business
* operations that needs validation. Often property access expressions
* extracting specific fields from captured API response data.
*
* Common patterns:
*
* - Property access for API response fields (customer.id, order.status)
* - Identifiers for captured variables from API operations
* - Array/object element access for nested data from API responses
* - Function call results for computed values (excluding API calls)
*
* AI expression construction: Ensure the actual value expression extracts
* the correct data from API responses according to the schema structure.
*/
y: IExpression;
}
/**
* Inequality validation predicate for TestValidator assertion.
*
* Used for negative validations and ensuring values have changed or differ
* from previous states.
*
* **Preferred over manual validation**: Use this instead of `IIfStatement`
* with throw statements for inequality checking.
*
* E2E testing scenarios:
*
* - Verifying values have changed after update API operations
* - Confirming different entities have different identifiers
* - Ensuring sensitive data is not exposed in API responses
* - Validating that values are NOT of unexpected types
*
* AI function calling usage: Use when business logic requires confirming
* differences or ensuring values have been modified by API operations.
* Important for testing update operations and data transformations.
*/
export interface INotEqualPredicate {
/** Type discriminator. */
type: "notEqualPredicate";
/**
* Descriptive title explaining what inequality is being validated.
*
* 🚨 CRITICAL: This MUST be a simple string value, NOT an expression! 🚨
*
* ❌ WRONG - DO NOT use expressions of any kind:
*
* - { type: "binaryExpression", operator: "+", left: "Value", right: " should
* differ" }
* - { type: "stringLiteral", value: "some string" }
* - Any IExpression types - this is NOT an expression field!
*
* ✅ CORRECT - Use direct string values only:
*
* - "Updated product name should differ from original"
* - Simple, complete descriptive text as a raw string
*
* Should clearly describe why the values should NOT be equal or what
* difference is expected. This helps with understanding test intent and
* debugging failures.
*
* Examples:
*
* - "Updated product name should differ from original"
* - "New order ID should not match previous order"
* - "Modified review should have different content"
* - "Response should not contain sensitive password data"
*
* AI title strategy: Focus on the business reason for the inequality check
* and what change or difference is being validated.
*/
title: string & tags.MinLength<1>;
/**
* First value expression for comparison.
*
* Typically represents the original value, previous state, or value that
* should be different from the second expression. Often captured from
* earlier API operations or represents a baseline state.
*
* Common patterns:
*
* - Original values before update API operations
* - Different entity identifiers from API responses
* - Previous state values captured from earlier API calls
* - Baseline data for comparison
*/
x: IExpression;
/**
* Second value expression for comparison.
*
* Represents the new value, current state, or value that should differ from
* the first expression. Often the result of API operations or updated data
* captured from API responses.
*
* Common patterns:
*
* - Updated values after modification API operations
* - Current entity states from API responses
* - New data from API responses
* - Transformed or processed values
*/
y: IExpression;
}
/**
* Conditional validation predicate for TestValidator assertion.
*
* Generates TestValidator validation calls based on boolean conditions. Used
* for validating business logic conditions, state checks, and conditional
* assertions that depend on runtime data or business rules from API
* responses.
*
* **Preferred over manual validation**: Use this instead of `IIfStatement`
* with throw statements for conditional validation logic.
*
* E2E testing scenarios:
*
* - Validating business rule compliance using API response data
* - Checking conditional states (user roles, feature flags) from API calls
* - Verifying complex boolean logic conditions involving captured data
* - Ensuring data meets business constraints after API operations
*
* AI function calling usage: Use when test validation depends on evaluating
* business conditions rather than simple equality checks. Essential for
* testing complex business logic and rule-based systems with API
* integration.
*/
export interface IConditionalPredicate {
/** Type discriminator. */
type: "conditionalPredicate";
/**
* Descriptive title explaining the conditional logic being validated.
*
* 🚨 CRITICAL: This MUST be a simple string value, NOT an expression! 🚨
*
* ❌ WRONG - DO NOT use expressions of any kind:
*
* - { type: "binaryExpression", operator: "+", left: "User", right: " should
* have access" }
* - { type: "stringLiteral", value: "some string" }
* - Any IExpression types - this is NOT an expression field!
*
* ✅ CORRECT - Use direct string values only:
*
* - "Premium customer should have access to exclusive features"
* - Simple, complete descriptive text as a raw string
*
* Should clearly describe the business condition or rule being tested and
* why it should be true. This helps understand the business context and
* debug failures when conditions aren't met.
*
* Examples:
*
* - "Premium customer should have access to exclusive features"
* - "Order total should exceed minimum purchase amount"
* - "Product should be available for selected category"
* - "User should have sufficient permissions for this operation"
*
* AI title strategy: Explain the business rule or condition being validated
* and its importance to the overall business workflow.
*/
title: string & tags.MinLength<1>;
/**
* Boolean expression representing the condition to be validated.
*
* Should evaluate to true when the business condition is met. Can be simple
* comparisons or complex logical expressions combining multiple business
* rules and data checks involving captured API response data.
*
* Common patterns:
*
* - Comparison expressions using captured data (customer.tier === "premium")
* - Logical combinations (hasPermission && isActive) with API response data
* - Type checks using typia.is<Type>(capturedValue)
* - Complex business rule evaluations with captured entities
*
* AI condition construction: Build conditions that accurately represent
* business rules and constraints relevant to the test scenario, using data
* captured from API operations.
*/
expression: IExpression;
}
/**
* General error validation predicate for TestValidator assertion.
*
* Generates TestValidator.error() call to verify that operations correctly
* throw errors under specific conditions. Used for testing error handling,
* business rule violations, and validation of both general errors and
* HTTP-specific error conditions in API operations.
*
* **Preferred over manual error testing**: Use this instead of `IIfStatement`
* with throw statements or try-catch blocks for error validation.
*
* E2E testing scenarios:
*
* - Testing business logic validation errors
* - Verifying general exception handling in utility functions
* - Confirming error throwing for invalid business operations
* - Testing HTTP status code responses from API operations (400, 401, 403, 404,
* etc.)
* - Testing authentication failures and authorization errors
* - Validating API request validation errors and conflict responses
*
* AI function calling usage: Use when business scenarios should intentionally
* fail to test error handling, including both general errors and specific
* HTTP status code validation from API operations.
*/
export interface IErrorPredicate {
/** Type discriminator. */
type: "errorPredicate";
/**
* Descriptive title explaining the error condition being tested.
*
* 🚨 CRITICAL: This MUST be a simple string value, NOT an expression! 🚨
*
* ❌ WRONG - DO NOT use expressions of any kind:
*
* - { type: "binaryExpression", operator: "+", left: "Should fail", right: "
* with invalid data" }
* - { type: "stringLiteral", value: "some string" }
* - Any IExpression types - this is NOT an expression field!
*
* ✅ CORRECT - Use direct string values only:
*
* - "Should fail business validation with invalid data"
* - Simple, complete descriptive text as a raw string
*
* Should clearly describe what error is expected and why it should occur.
* This helps understand the negative test case purpose and assists with
* debugging when expected errors don't occur.
*
* Examples:
*
* **General Error Testing:**
*
* - "Should fail business validation with invalid data"
* - "Should throw error for duplicate entity creation"
* - "Should reject operation with insufficient business context"
* - "Should validate required business rule constraints"
*
* **HTTP Error Testing:**
*
* - "Should return 401 for invalid authentication credentials"
* - "Should return 403 for unauthorized customer access"
* - "Should return 400 for missing required fields in registration"
* - "Should return 404 for non-existent product ID"
* - "Should return 409 for duplicate email registration"
* - "Should return 422 for invalid business data format"
* - "Should return 429 for rate limit exceeded"
*
* AI title strategy: Focus on the specific error condition and business
* context that should trigger the failure. Include HTTP status codes when
* testing API error responses for clarity and debugging assistance.
*/
title: string & tags.MinLength<1>;
/**
* Arrow function containing the operation that should throw an error.
*
* Encapsulates the API operation or business logic that is expected to
* fail. The function should contain realistic API operations (using
* IApiOperateStatement within the function body) with invalid data or
* conditions that trigger appropriate error responses.
*
* **Note**: The function body can contain IApiOperateStatement calls since
* this is specifically for testing API error conditions.
*
* **General Error Testing Patterns:**
*
* - API calls with invalid business data that should trigger general errors
* - API operations with malformed or missing required data
* - Business rule violations that should be rejected by API operations
* - General validation failures and custom error conditions
*
* **HTTP Error Testing Patterns:**
*
* **Authentication Errors (401)**:
*
* - API calls with invalid or expired tokens
* - Login attempts with wrong credentials
* - Access without required authentication headers
*
* **Authorization Errors (403)**:
*
* - API calls with insufficient user permissions
* - Access to restricted resources by unauthorized users
* - Operations requiring admin privileges by regular users
*
* **Validation Errors (400, 422)**:
*
* - API calls with missing required fields
* - Invalid data format or type in request body
* - Business rule violations in API parameters
*
* **Not Found Errors (404)**:
*
* - API calls with non-existent resource IDs
* - Access to deleted or unavailable resources
* - Invalid endpoint or resource paths
*
* **Conflict Errors (409)**:
*
* - Duplicate resource creation attempts
* - Concurrent modification conflicts
* - Business rule conflicts (e.g., duplicate emails)
*
* **Rate Limiting Errors (429)**:
*
* - Excessive API calls within time window
* - Quota exceeded for API operations
* - Throttling due to usage limits
*
* **Server Errors (5xx)**:
*
* - API calls that trigger internal server errors
* - Operations that cause service unavailability
* - Database connection or processing failures
*
* AI function construction: Create realistic error scenarios that test
* actual business constraints and error handling. Focus on API operation
* error conditions that should throw errors, including both general
* exceptions and specific HTTP status code responses.
*/
function: IArrowFunction;
}
/**
* Property assignment for object literal construction.
*
* Represents individual key-value pairs within object literals. Critical for
* building request bodies, configuration objects, and structured data that
* conforms to API schemas and business requirements, particularly for use in
* `IApiOperateStatement` operations.
*
* E2E testing importance: Each property assignment must align with DTO schema
* requirements to ensure valid API requests and realistic business data
* representation.
*
* AI function calling requirement: Property names and value types must match
* target schema definitions exactly, especially when used for API operation
* parameters.
*/
export interface IPropertyAssignment {
/**
* Type discriminator for property assignments.
*
* Always "propertyAssignment" to distinguish from other object construction
* mechanisms in the AST.
*/
type: "propertyAssignment";
/**
* Property name (object key).
*
* Must correspond to actual property names defined in target DTO schemas,
* API specifications, or business data models. Should use camelCase
* convention matching TypeScript interfaces.
*
* **API context**: When used in request bodies for API operations, must
* exactly match the expected parameter names in the API specification.
*
* Examples:
*
* - "name" for entity names in API requests
* - "email" for contact information in API calls
* - "price" for monetary values in business API operations
* - "createdAt" for timestamps in API responses
* - "isActive" for boolean flags in API parameters
*
* AI validation requirement: Ensure property names exist in the target
* schema and follow exact naming conventions used in API specifications.
*/
name: string & tags.MinLength<1>;
/**
* Property value expression.
*
* Expression that evaluates to the property value. Type must match the
* expected type for this property in the target schema. Should represent
* realistic business data appropriate for the property's purpose.
*
* - **⚠️ CRITICAL AI RESTRICTION: This MUST be an AST expression, NOT a raw
* value! ⚠️**
* - **❌ WRONG: "John Doe" (raw string)**
* - **❌ WRONG: 123 (raw number)**
* - **❌ WRONG: true (raw boolean)**
* - **✅ CORRECT: IStringLiteral, INumericLiteral, IBooleanLiteral (AST
* expressions)**
*
* **API usage**: When used in API operation parameters, must generate
* values compatible with the API specification requirements.
*
* Common patterns:
*
* - String literals for names, descriptions, codes in API requests
* - Numeric literals for quantities, prices, scores in API calls
* - Boolean literals for flags and states in API parameters
* - Object literals for nested business data in API requests
* - Array literals for collections in API operations
* - Random generators for variable test data in API calls
* - Identifiers for referencing captured data from previous API operations
*
* AI type matching: Must generate expressions that produce values
* compatible with the target property's schema type and API constraints.
*/
value: IExpression;
}
}AST (Abstract Syntax Tree) structures are inherently recursive with infinite depth and countless union types. Therefore, creating AI function calling schemas for AST should never be done manually. It must be automatically generated by a compiler to ensure both stability and productivity.
The typia.llm.application<App, Model, Options>() function serves as the cornerstone of this approach. This powerful utility automatically generates comprehensive AI function calling schemas from TypeScript type definitions. By leveraging compile-time type analysis, it creates schemas that are not only type-safe but also include rich metadata and validation rules embedded directly in the type system.
The function supports multiple AI models through its generic parameters, allowing for model-specific optimizations and feature support. The options parameter enables fine-tuning of schema generation, including reference handling, description enrichment, and validation strictness. This compiler-driven approach eliminates the manual effort and potential errors associated with hand-crafted schemas while providing superior type safety and maintainability.
Comments over Prompts
export namespace AutoBeDatabase {
/**
* Interface representing a single Prisma schema file within the application.
*
* Each file focuses on a specific business domain and contains related
* models. File organization follows domain-driven design principles as seen
* in the uploaded schemas.
*/
export interface IFile {
/**
* Name of the schema file to be generated.
*
* Should follow the naming convention: "schema-{number}-{domain}.prisma"
* Examples: "schema-02-systematic.prisma", "schema-03-actors.prisma" The
* number indicates the dependency order for schema generation.
*/
filename: string & tags.Pattern<"^[a-zA-Z0-9._-]+\\.prisma$">;
/**
* Business domain namespace that groups related models.
*
* Used in Prisma documentation comments as "@\namespace directive".
* Examples from uploaded schemas: "Systematic", "Actors", "Sales", "Carts",
* "Orders", "Coupons", "Coins", "Inquiries", "Favorites", "Articles"
*/
namespace: string;
/**
* Array of Prisma models (database tables) within this domain.
*
* Each model represents a business entity or concept within the namespace.
* Models can reference each other through foreign key relationships.
*/
models: IModel[];
}
/**
* Interface representing a single Prisma model (database table).
*
* Based on the uploaded schemas, models follow specific patterns:
*
* - Main business entities (e.g., shopping_sales, shopping_customers)
* - Snapshot/versioning entities for audit trails (e.g.,
* shopping_sale_snapshots)
* - Junction tables for M:N relationships (e.g.,
* shopping_cart_commodity_stocks)
* - Materialized views for performance (prefixed with mv_)
*/
export interface IModel {
/**
* Name of the Prisma model (database table name).
*
* Should follow snake_case convention with domain prefix. Examples:
* "shopping_customers", "shopping_sale_snapshots", "bbs_articles"
* Materialized views use "mv_" prefix: "mv_shopping_sale_last_snapshots"
*/
name: string & tags.Pattern<"^[a-z][a-z0-9_]*$">;
/**
* Detailed description explaining the business purpose and usage of the
* model.
*
* Should include:
*
* - Business context and purpose
* - Key relationships with other models
* - Important behavioral notes or constraints
* - References to related entities using "{@\link ModelName}" syntax Example:
* "Customer information, but not a person but a **connection** basis..."
*/
description: string;
/**
* Indicates whether this model represents a materialized view for
* performance optimization.
*
* Materialized views are read-only computed tables that cache complex query
* results. They're marked as "@\hidden" in documentation and prefixed with
* "mv_" in naming. Examples: mv_shopping_sale_last_snapshots,
* mv_shopping_cart_commodity_prices
*/
material: boolean;
//----
// FIELDS
//----
/**
* The primary key field of the model.
*
* In all uploaded schemas, primary keys are always UUID type with "@\id"
* directive. Usually named "id" and marked with "@\db.Uuid" for PostgreSQL
* mapping.
*/
primaryField: IPrimaryField;
/**
* Array of foreign key fields that reference other models.
*
* These establish relationships between models and include Prisma relation
* directives. Can be nullable (optional relationships) or required
* (mandatory relationships). May have unique constraints for 1:1
* relationships.
*/
foreignFields: IForeignField[];
/**
* Array of regular data fields that don't reference other models.
*
* Include business data like names, descriptions, timestamps, flags,
* amounts, etc. Common patterns: created_at, updated_at, deleted_at for
* soft deletion and auditing.
*/
plainFields: IPlainField[];
//----
// INDEXES
//----
/**
* Array of unique indexes for enforcing data integrity constraints.
*
* Ensure uniqueness across single or multiple columns. Examples: unique
* email addresses, unique codes within a channel, unique combinations like
* (channel_id, nickname).
*/
uniqueIndexes: IUniqueIndex[];
/**
* Array of regular indexes for query performance optimization.
*
* Speed up common query patterns like filtering by foreign keys, date
* ranges, or frequently searched fields. Examples: indexes on created_at,
* foreign key fields, search fields.
*/
plainIndexes: IPlainIndex[];
/**
* Array of GIN (Generalized Inverted Index) indexes for full-text search.
*
* Used specifically for PostgreSQL text search capabilities using trigram
* operations. Applied to text fields that need fuzzy matching or partial
* text search. Examples: searching names, nicknames, titles, content
* bodies.
*/
ginIndexes: IGinIndex[];
}
}@autobe invests significantly more effort in embedding coding rules as comments within the types used for AI function calling rather than relying on system prompts to enforce these rules.
This approach stems from a critical observation: AI models often fail to consistently follow system prompt rules, and these rules are frequently ignored entirely when context grows large. In contrast, description information written in function calling schemas is reliably followed by AI models. When AI generates information for a type specified through function calling, it references the type’s description information again, making type-level comments far more effective than system prompts in coding agents.
The AutoBeDatabase.IFile and AutoBeDatabase.IModel types exemplify this approach by meticulously documenting the rules that must be followed for each interface and property type. For example, the filename property must follow the schema-{number}-{domain}.prisma format, and when defining database models, the name property must use snake_case convention with domain prefixes like shopping_customers or bbs_articles. Each comment provides concrete examples and specific constraints that guide the AI toward generating compliant code structures.
This comment-driven approach ensures that coding rules are embedded directly where the AI encounters them during code generation, creating a more reliable and maintainable system than traditional prompt-based instruction methods.
Validation Feedback
undefined
import { ILlmFunction } from "./ILlmFunction";
import { ILlmSchema } from "./ILlmSchema";
import { IValidation } from "./IValidation";
/**
* Application of LLM function calling.
*
* `ILlmApplication` is a data structure representing a collection of
* {@link ILlmFunction LLM function calling schemas}, composed from a native
* TypeScript class (or interface) type by the `typia.llm.application<App>()`
* function.
*
* Also, there can be some parameters (or their nested properties) which must be
* composed by Human, not by LLM. File uploading feature or some sensitive
* information like secret key (password) are the examples. In that case, you
* can separate the function parameters to both LLM and human sides by
* configuring the {@link ILlmApplication.IConfig.separate} property. The
* separated parameters are assigned to the {@link ILlmFunction.separated}
* property.
*
* For reference, when both LLM and Human filled parameter values to call, you
* can merge them by calling the {@link HttpLlm.mergeParameters} function. In
* other words, if you've configured the {@link ILlmApplication.IConfig.separate}
* property, you have to merge the separated parameters before the function call
* execution.
*
* @author Jeongho Nam - https://github.com/samchon
* @reference https://platform.openai.com/docs/guides/function-calling
*/
export interface ILlmApplication<Class extends object = any> {
/**
* List of function metadata.
*
* List of function metadata that can be used for the LLM function call.
*/
functions: ILlmFunction[];
/** Configuration for the application. */
config: ILlmApplication.IConfig<Class>;
/**
* Class type, the source of the LLM application.
*
* This property is just for the generic type inference, and its value is
* always `undefined`.
*/
__class?: Class | undefined;
}
export namespace ILlmApplication {
/** Configuration for application composition. */
export interface IConfig<Class extends object = any>
extends ILlmSchema.IConfig {
/**
* Separator function for the parameters.
*
* When composing parameter arguments through LLM function call, there can
* be a case that some parameters must be composed by human, or LLM cannot
* understand the parameter.
*
* For example, if the parameter type has configured
* {@link ILlmSchema.IString.contentMediaType} which indicates file
* uploading, it must be composed by human, not by LLM (Large Language
* Model).
*
* In that case, if you configure this property with a function that
* predicating whether the schema value must be composed by human or not,
* the parameters would be separated into two parts.
*
* - {@link ILlmFunction.separated.llm}
* - {@link ILlmFunction.separated.human}
*
* When writing the function, note that returning value `true` means to be a
* human composing the value, and `false` means to LLM composing the value.
* Also, when predicating the schema, it would better to utilize the
* {@link LlmTypeChecker} like features.
*
* @default null
* @param schema Schema to be separated.
* @returns Whether the schema value must be composed by human or not.
*/
separate: null | ((schema: ILlmSchema) => boolean);
/**
* Custom validation functions for specific class methods.
*
* The `validate` property allows you to provide custom validation functions
* that will replace the default validation behavior for specific methods
* within the application class. When specified, these custom validators
* take precedence over the standard type validation generated by
* `typia.llm.application()`.
*
* This feature is particularly useful when you need to:
*
* - Implement business logic validation beyond type checking
* - Add custom constraints that cannot be expressed through type annotations
* - Provide more specific error messages for AI agents
* - Validate dynamic conditions based on runtime state
*
* Each validation function receives the same arguments as its corresponding
* method and must return an {@link IValidation} result. On validation
* success, it should return `{ success: true, data }`. On failure, it
* should return `{ success: false, data, errors }` with detailed error
* information that helps AI agents understand and correct their mistakes.
*
* @default null
*/
validate: null | Partial<ILlmApplication.IValidationHook<Class>>;
}
/**
* Type for custom validation function hooks.
*
* `IValidationHook` defines the structure for custom validation functions
* that can be provided for each method in the application class. It creates a
* mapped type where each property corresponds to a method in the class, and
* the value is a validation function for that method's parameters.
*
* The validation hook functions:
*
* - Receive the same argument type as the original method
* - Must return an {@link IValidation} result indicating success or failure
* - Replace the default type validation when specified
* - Enable custom business logic and runtime validation
*
* Type constraints:
*
* - Only methods (functions) from the class can have validation hooks
* - Non-function properties are typed as `never` and cannot be validated
* - The validation function must match the method's parameter signature
*
* @template Class The application class type containing methods to validate
*/
export type IValidationHook<Class extends object> = {
[K in keyof Class]?: Class[K] extends (args: infer Argument) => unknown
? (input: unknown) => IValidation<Argument>
: never;
};
}undefined
import { ILlmSchema } from "./ILlmSchema";
import { IValidation } from "./IValidation";
/**
* LLM function metadata.
*
* `ILlmFunction` is an interface representing a function metadata, which has
* been used for the LLM (Language Large Model) function calling. Also, it's a
* function structure containing the function {@link name}, {@link parameters} and
* {@link output return type}.
*
* If you provide this `ILlmFunction` data to the LLM provider like "OpenAI",
* the "OpenAI" will compose a function arguments by analyzing conversations
* with the user. With the LLM composed arguments, you can execute the function
* and get the result.
*
* By the way, do not ensure that LLM will always provide the correct arguments.
* The LLM of present age is not perfect, so that you would better to validate
* the arguments before executing the function. I recommend you to validate the
* arguments before execution by using
* [`typia`](https://github.com/samchon/typia) library.
*
* @author Jeongho Nam - https://github.com/samchon
* @reference https://platform.openai.com/docs/guides/function-calling
*/
export interface ILlmFunction {
/**
* Representative name of the function.
*
* @maxLength 64
*/
name: string;
/** List of parameter types. */
parameters: ILlmSchema.IParameters;
/**
* Collection of separated parameters.
*
* Filled only when {@link ILlmApplication.IConfig.separate} is configured.
*/
separated?: ILlmFunction.ISeparated;
/**
* Expected return type.
*
* If the function returns nothing (`void`), the `output` value would be
* `undefined`.
*/
output?: ILlmSchema | undefined;
/**
* Description of the function.
*
* For reference, the `description` is a critical property for teaching the
* purpose of the function to LLMs (Large Language Models). LLMs use this
* description to determine which function to call.
*
* Also, when the LLM converses with the user, the `description` explains the
* function to the user. Therefore, the `description` property has the highest
* priority and should be carefully considered.
*/
description?: string | undefined;
/**
* Whether the function is deprecated or not.
*
* If the `deprecated` is `true`, the function is not recommended to use.
*
* LLM (Large Language Model) may not use the deprecated function.
*/
deprecated?: boolean | undefined;
/**
* Category tags for the function.
*
* You can fill this property by the `@tag ${name}` comment tag.
*/
tags?: string[] | undefined;
/**
* Validate function of the arguments.
*
* You know what? LLM (Large Language Model) like OpenAI takes a lot of
* mistakes when composing arguments in function calling. Even though `number`
* like simple type is defined in the {@link parameters} schema, LLM often
* fills it just by a `string` typed value.
*
* In that case, you have to give a validation feedback to the LLM by using
* this `validate` function. The `validate` function will return detailed
* information about every type errors about the arguments.
*
* And in my experience, OpenAI's `gpt-4o-mini` model tends to construct an
* invalid function calling arguments at the first trial about 50% of the
* time. However, if correct it through this `validate` function, the success
* rate soars to 99% at the second trial, and I've never failed at the third
* trial.
*
* > If you've {@link separated} parameters, use the
* > {@link ILlmFunction.ISeparated.validate} function instead when validating
* > the LLM composed arguments.
*
* > In that case, This `validate` function would be meaningful only when you've
* > merged the LLM and human composed arguments by
* > {@link HttpLlm.mergeParameters} function.
*
* @param args Arguments to validate
* @returns Validation result
*/
validate: (args: unknown) => IValidation<unknown>;
}
export namespace ILlmFunction {
/** Collection of separated parameters. */
export interface ISeparated {
/**
* Parameters that would be composed by the LLM.
*
* Even though no property exists in the LLM side, the `llm` property would
* have at least empty object type.
*/
llm: ILlmSchema.IParameters;
/** Parameters that would be composed by the human. */
human: ILlmSchema.IParameters | null;
/**
* Validate function of the separated arguments.
*
* If LLM part of separated parameters has some properties, this `validate`
* function will be filled for the {@link llm} type validation.
*
* > You know what? LLM (Large Language Model) like OpenAI takes a lot of
* > mistakes when composing arguments in function calling. Even though
* > `number` like simple type is defined in the {@link parameters} schema, LLM
* > often fills it just by a `string` typed value.
*
* > In that case, you have to give a validation feedback to the LLM by using
* > this `validate` function. The `validate` function will return detailed
* > information about every type errors about the arguments.
*
* > And in my experience, OpenAI's `gpt-4o-mini` model tends to construct an
* > invalid function calling arguments at the first trial about 50% of the
* > time. However, if correct it through this `validate` function, the
* > success rate soars to 99% at the second trial, and I've never failed at
* > the third trial.
*
* @param args Arguments to validate
* @returns Validate result
*/
validate?: ((args: unknown) => IValidation<unknown>) | undefined;
}
}undefined
/**
* Union type representing the result of type validation
*
* This is the return type of {@link typia.validate} functions, returning
* {@link IValidation.ISuccess} on validation success and
* {@link IValidation.IFailure} on validation failure. When validation fails, it
* provides detailed, granular error information that precisely describes what
* went wrong, where it went wrong, and what was expected.
*
* This comprehensive error reporting makes `IValidation` particularly valuable
* for AI function calling scenarios, where Large Language Models (LLMs) need
* specific feedback to correct their parameter generation. The detailed error
* information is used by ILlmFunction.validate() to provide validation feedback
* to AI agents, enabling iterative correction and improvement of function
* calling accuracy.
*
* This type uses the Discriminated Union pattern, allowing type specification
* through the success property:
*
* ```typescript
* const result = typia.validate<string>(input);
* if (result.success) {
* // IValidation.ISuccess<string> type
* console.log(result.data); // validated data accessible
* } else {
* // IValidation.IFailure type
* console.log(result.errors); // detailed error information accessible
* }
* ```
*
* @author Jeongho Nam - https://github.com/samchon
* @template T The type to validate
*/
export type IValidation<T = unknown> =
| IValidation.ISuccess<T>
| IValidation.IFailure;
export namespace IValidation {
/**
* Interface returned when type validation succeeds
*
* Returned when the input value perfectly conforms to the specified type T.
* Since success is true, TypeScript's type guard allows safe access to the
* validated data through the data property.
*
* @template T The validated type
*/
export interface ISuccess<T = unknown> {
/** Indicates validation success */
success: true;
/** The validated data of type T */
data: T;
}
/**
* Interface returned when type validation fails
*
* Returned when the input value does not conform to the expected type.
* Contains comprehensive error information designed to be easily understood
* by both humans and AI systems. Each error in the errors array provides
* precise details about validation failures, including the exact path to the
* problematic property, what type was expected, and what value was actually
* provided.
*
* This detailed error structure is specifically optimized for AI function
* calling validation feedback. When LLMs make type errors during function
* calling, these granular error reports enable the AI to understand exactly
* what went wrong and how to fix it, improving success rates in subsequent
* attempts.
*
* Example error scenarios:
*
* - Type mismatch: expected "string" but got number 5
* - Format violation: expected "string & Format<'uuid'>" but got
* "invalid-format"
* - Missing properties: expected "required property 'name'" but got undefined
* - Array type errors: expected "Array<string>" but got single string value
*
* The errors are used by ILlmFunction.validate() to provide structured
* feedback to AI agents, enabling them to correct their parameter generation
* and achieve improved function calling accuracy.
*/
export interface IFailure {
/** Indicates validation failure */
success: false;
/** The original input data that failed validation */
data: unknown;
/** Array of detailed validation errors */
errors: IError[];
}
/**
* Detailed information about a specific validation error
*
* Each error provides granular, actionable information about validation
* failures, designed to be immediately useful for both human developers and
* AI systems. The error structure follows a consistent format that enables
* precise identification and correction of type mismatches.
*
* This error format is particularly valuable for AI function calling
* scenarios, where LLMs need to understand exactly what went wrong to
* generate correct parameters. The combination of path, expected type name,
* actual value, and optional human-readable description provides the AI with
* comprehensive context to make accurate corrections, which is why
* ILlmFunction.validate() can achieve such high success rates in validation
* feedback loops.
*
* The value field can contain any type of data, including `undefined` when
* dealing with missing required properties or null/undefined validation
* scenarios. This allows for precise error reporting in cases where the AI
* agent omits required fields or provides null/undefined values
* inappropriately.
*
* Real-world examples from AI function calling:
*
* {
* path: "$input.member.age",
* expected: "number",
* value: "25" // AI provided string instead of number
* }
*
* {
* path: "$input.count",
* expected: "number & Type<'uint32'>",
* value: 20.75 // AI provided float instead of uint32
* }
*
* {
* path: "$input.categories",
* expected: "Array<string>",
* value: "technology" // AI provided string instead of array
* }
*
* {
* path: "$input.id",
* expected: "string & Format<'uuid'>",
* value: "invalid-uuid-format" // AI provided malformed UUID
* }
*
* {
* path: "$input.user.name",
* expected: "string",
* value: undefined // AI omitted required property
* }
*/
export interface IError {
/**
* The path to the property that failed validation
*
* Dot-notation path using $input prefix indicating the exact location of
* the validation failure within the input object structure. Examples
* include "$input.member.age", "$input.categories[0]",
* "$input.user.profile.email"
*/
path: string;
/**
* The expected type name or type expression
*
* Technical type specification that describes what type was expected at
* this path. This follows TypeScript-like syntax with embedded constraint
* information, such as "string", "number & Type<'uint32'>",
* "Array<string>", "string & Format<'uuid'> & MinLength<8>", etc.
*/
expected: string;
/**
* The actual value that caused the validation failure
*
* This field contains the actual value that was provided but failed
* validation. Note that this value can be `undefined` in cases where a
* required property is missing or when validating against undefined
* values.
*/
value: unknown;
/**
* Optional human-readable description of the validation error
*
* This field is rarely populated in standard typia validation and is
* primarily intended for specialized AI agent libraries or custom
* validation scenarios that require additional context beyond the technical
* type information. Most validation errors rely solely on the path,
* expected, and value fields for comprehensive error reporting.
*/
description?: string;
}
}Does AI function calling always produce type-valid AST data? The answer is no. AI frequently experiences hallucinations even during function calling, generating AST data that is not type-valid. To correct these AI errors, validation feedback must be provided back to the AI.
The typia.llm.application<App, Model, Options>() function used by @autobe to create AI function calling schemas for AST data includes a built-in runtime type checker specialized for AI validation feedback. This validator doesn’t just identify type violations; it generates detailed, AI-friendly error messages that help the model understand exactly what went wrong and how to fix it.
Even when AI function calling produces AST data that is type-correct, there are cases where the data fails to follow @autobe’s coding rules or contains contradictions that make conversion to programming code impossible. In these scenarios, @autobe’s custom-developed compiler’s built-in compilation feedback feature activates to assist in AI correction.
This dual-layer validation system ensures that both type safety and business rule compliance are maintained throughout the code generation process. The compiler-level feedback provides semantic validation beyond simple type checking, catching logical inconsistencies and rule violations that could lead to non-functional generated code.
By combining runtime type validation with semantic rule validation, @autobe creates a robust feedback loop that continuously improves AI output quality while maintaining the integrity of the generated codebase. This approach transforms potential AI hallucinations from fatal errors into learning opportunities, allowing the system to iteratively refine its output until it meets all requirements.