
Benchmarks on Local LLMs about Backend Generation, Monthly
TL;DR
- AutoBe’s first proper benchmark — a follow-up to the informal measurements I’ve been posting to r/LocalLLaMA over the past year.
- Thanks to the function calling harness, the gap between frontier and local models has effectively disappeared. This is the last round that includes the expensive frontier models.
- From next month, only small and cheap local models compete. In two or three months, the leaderboard expands to include frontend automation.
1. Preface
AutoBe is an open-source AI agent that generates an entire backend from a single natural-language instruction. Something as short as “build me a shopping mall backend with products, carts, orders, and payments” is enough. From that one sentence, six artifacts come out at once:
- Requirements analysis (SRS)
- DB design (ERD)
- API specification (OpenAPI v3.1)
- E2E test code
- Full NestJS implementation
- Type-safe SDK
Under the hood, a five-phase pipeline runs through Analyze → Database → Interface → Test → Realize. The LLM doesn’t write code as free-form text. At each phase it fills a predefined AST structure via function calling, and AutoBe’s compiler turns that structure into actual source files.
Over the past year, I’ve been posting progress updates from this project to r/LocalLLaMA. As I noted in each post, those measurements lacked controlled variables — they weren’t benchmarks in any rigorous sense. This post is the first proper benchmark to take their place.
Two things matter most this round. First, with the function calling harness now complete, the gap between frontier and local models has effectively disappeared. Second, that’s why this is the last round we include expensive frontier models in our comparison set.
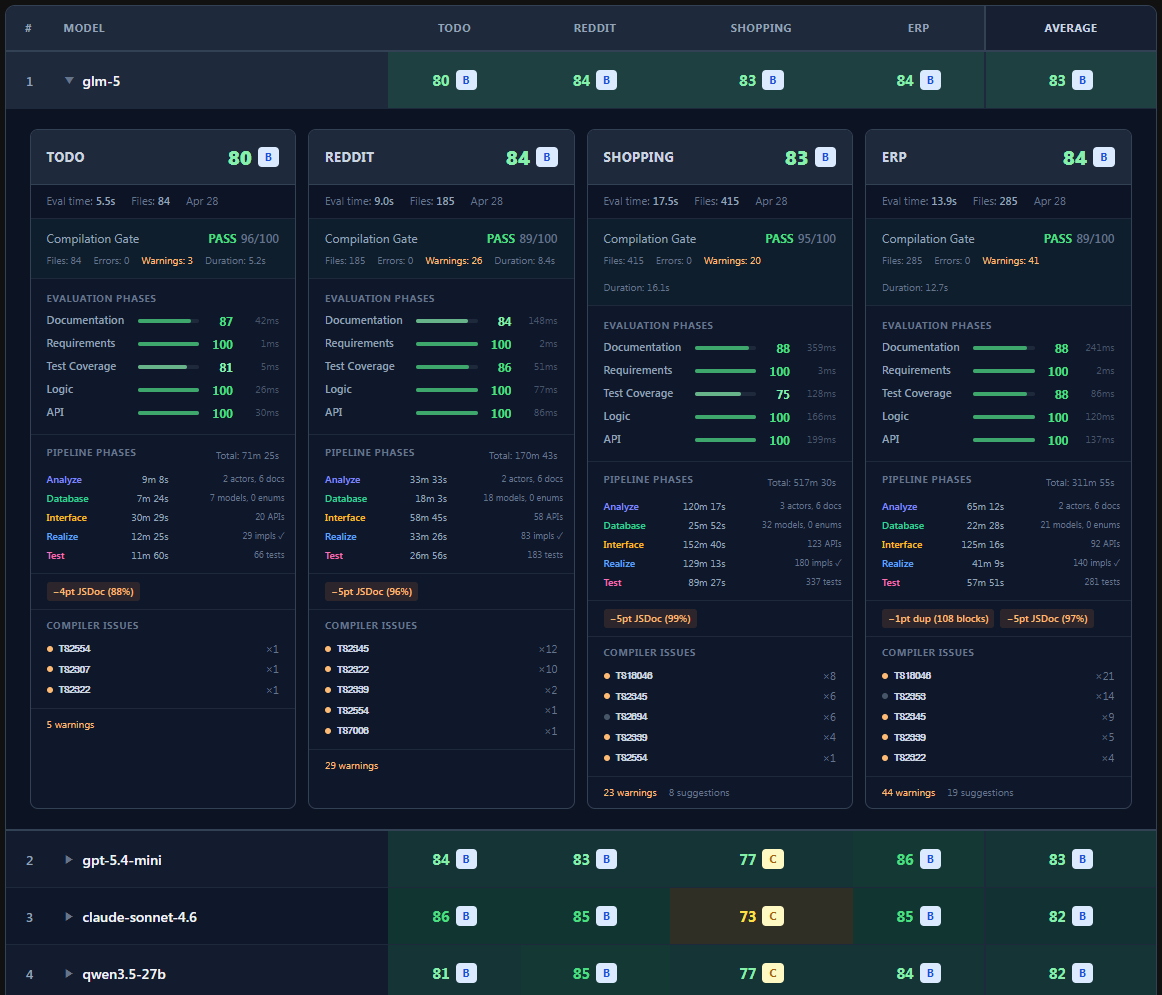
With controlled variables, a compilation gate, and a six-axis weighted rubric, we built a measurement that decomposes the score into about 15–20 dimensions per project. The result: the DB / API design that GPT 5.4 produces is indistinguishable from what qwen3.5-35b-a3b produces, and the same goes for the logic code from Claude Sonnet 4.6 vs. qwen3.5-27b.
From next month, small and cheap local models go head-to-head. In two or three months, frontend automation joins the leaderboard.
- Github Repository: https://github.com/wrtnlabs/autobe
- Benchmark Dashboard: https://autobe.dev/benchmark — the live leaderboard (also embedded in §4)
- Benchmark Outputs: https://github.com/wrtnlabs/autobe-examples — the actual backend each model produced
2. The Old Benchmark
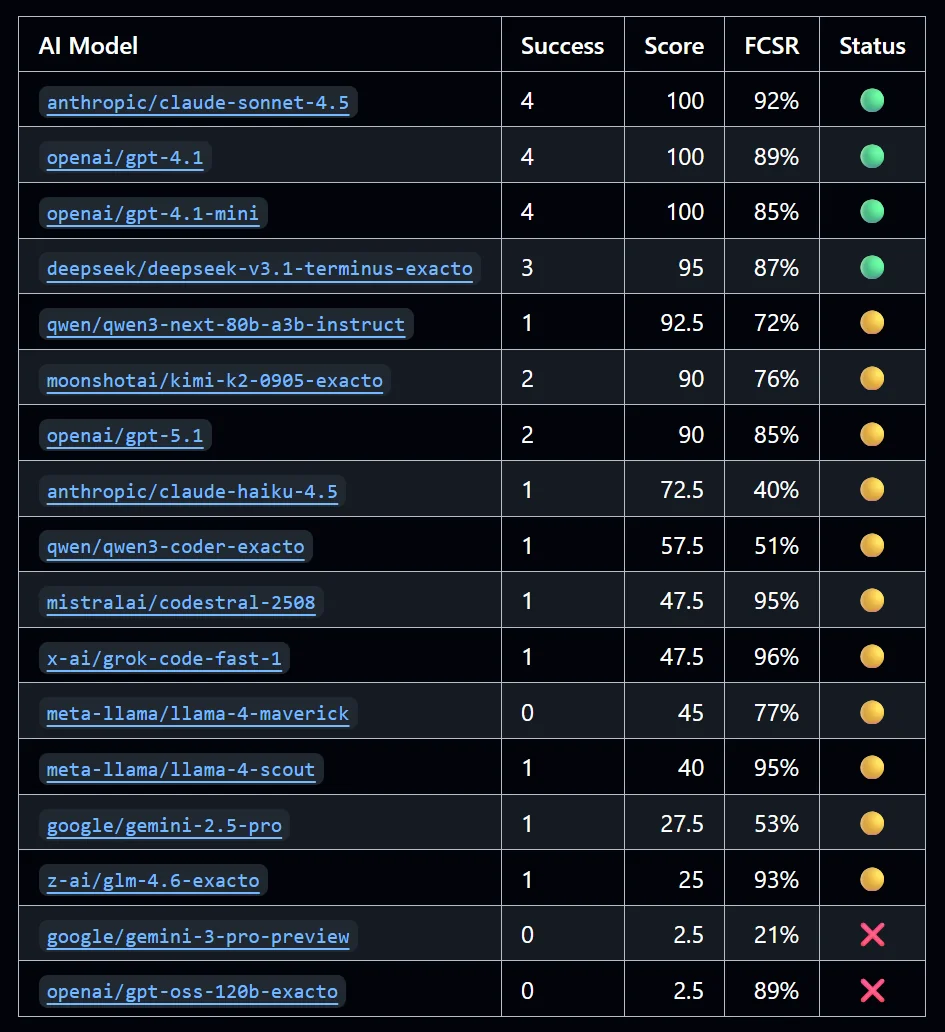
https://www.reddit.com/r/LocalLLaMA/comments/1p2ziil/hardcore_function_calling_benchmark_in_backend/
The image above is the body of the most recent r/LocalLLaMA post — Hardcore function calling benchmark in backend coding agent. As I noted in that post itself, those benchmarks had the following limitations:
- No controlled variables. Nothing was held constant for comparing models.
- Crude scoring. For each of AutoBe’s five phases (Analyze / Database / Interface / Test / Realize), Pass = +20, Fail = +0. A small deduction if there were compile errors. That was it.
- The only meaningful signal was FCSR (function calling success rate on the first try) — how deep into a complex type schema can a local model still complete a function call? That ceiling. Beyond that, there wasn’t much to claim.
- And yet the response from the r/LocalLLaMA community was extraordinary. Thanks again to everyone there.
Let me unpack what I meant by complex type schemas in point 3, then move on to §3.
Each of AutoBe’s five phases has its own AST that the LLM has to fill. The output from each AST goes straight into a compiler for validation.
| Phase | Structure the LLM Fills | Compiler Validation |
|---|---|---|
| Requirements | AutoBeAnalyze — Structured SRS | Structure check |
| Database | AutoBeDatabase — DB schema AST | AutoBeDatabase compiler |
| API Design | AutoBeOpenApi — OpenAPI v3.1 spec | AutoBeOpenApi compiler |
| Testing | AutoBeTest — 34 expression types | AutoBeTest compiler |
| Implementation | Modularized code (Collector / Transformer / Operation) | TypeScript compiler |
What these ASTs share is recursive union types extending without bound. As one example, OpenAPI’s IJsonSchema is a union of exactly 10 variants that reference themselves and nest to arbitrary depth. The probability that a model gets one of these right on the first try drops into the single-digit percent range.
export namespace AutoBeOpenApi {
export type IJsonSchema =
| IJsonSchema.IConstant
| IJsonSchema.IBoolean
| IJsonSchema.IInteger
| IJsonSchema.INumber
| IJsonSchema.IString
| IJsonSchema.IArray // items: IJsonSchema ← recursive
| IJsonSchema.IObject // properties: Record<string, IJsonSchema> ← recursive
| IJsonSchema.IReference
| IJsonSchema.IOneOf // oneOf: IJsonSchema[] ← recursive
| IJsonSchema.INull;
}So how deep into this each model can still hold up — that was the only meaningful signal in those past posts. And the limit of those benchmarks.
So what should a proper benchmark actually look like?
3. This Benchmark Is Different
This benchmark is the first one with a proper shape. Three things have changed since last time: controlled variables, the scoring rubric, and the precision of the measurement itself.
3.1. Controlled Variables, Locked Down
We swap only the model — everything else is held constant. Same four reference projects (todo / reddit / shopping / erp), same system prompts, same five-phase pipeline, same retry policy. For the first time, model-to-model comparison actually means something.
3.2. A Clear Scoring Rubric
With controls in place, the next question was what to measure and how. Five Pass/Fail × 20 points was no longer the answer. This round’s scoring is a 100-point rubric: a compilation gate, six weighted evaluation axes, and a penalty system.
| Phase | Weight | What it measures |
|---|---|---|
| Compilation Gate | PASS / FAIL | TypeScript + DB compile passes. On a soft pass, a multiplier applies to every phase score. |
| Documentation | 7% | docs/ folder, README, depth of documentation |
| Requirements | 18% | controller ↔ provider mapping, architectural completeness |
| Test Coverage | 23% | route-level coverage, absolute test count, assertion ratio |
| Logic Completeness | 30% | TODO / FIXME / empty method / stub patterns (largest weight) |
| API Completeness | 7% | ratio of substantive (non-empty) endpoints |
| Golden Set | 15% (optional, not run this round) | live-server pass rate by category (auth / crud / query / negative / workflow) |
On top of that, items like code duplication, missing JSDoc, and DB ↔ TypeScript schema mismatches are deducted as separate penalties (capped at -20 total). Because the rubric is multi-dimensional, you can see which model is strong on which axis — and weak on which.
3.3. Resolution and Reproducibility
For this rubric to be precise, two things have to hold: the resolution has to be fine enough, and the same artifact has to score the same when anyone re-measures it.
Resolution first. The score isn’t a single binary “did it pass.” It decomposes across four reference projects into 6 phases × metrics ≈ 15–20 dimensions. You can pinpoint exactly where a model writes solid logic but skimps on docs, or fills tests while leaving APIs empty.
Reproducibility matters more. The core evaluation phases score the artifact through 100% static analysis: AST traversal, pattern matching, route extraction, compiler diagnostics. Nothing in the pipeline is let an LLM grade it. Same artifact, same score, regardless of who runs it. That’s the foundation that makes model-to-model comparison even possible.
On these three axes, model comparison finally means something. Let’s see what that meaning looks like in the data.
4. The Result — Last Frontier-Inclusive Run
4.1. First Impression — A Narrowed Band
One look at the dashboard tells the story. Scores cluster in a narrow band, and the old picture — frontier models taking the top spot by default — has broken.
The biggest reason the band tightened is that the function calling harness has been completed. A large share of the model-to-model gap used to live in whether the model gets a complex type right on the first try, and the harness, with retries and structured diagnostics, has compensated for exactly that. Almost every model now produces stable output. The end result: the most expensive frontier model and a small local model you can run on a personal laptop are effectively on the same line — a picture we hadn’t seen in any previous round.
4.2. The Local-Model Surge
Start with the total ranking. First place isn’t a frontier model — it’s GLM 5. It edged past both Claude Sonnet 4.6 and GPT 5.4-mini. Right behind it is qwen3.5-27b, which left every other heavyweight in the local camp (kimi-k2.5, deepseek-v4-pro, qwen3.5-397b-a17b) behind to land directly after the frontier cluster.
The same picture holds when you slice by dimension.
- The DB / API designs from GPT 5.4 and
qwen3.5-35b-a3bare essentially indistinguishable. - The same goes for the logic code from Claude Sonnet 4.6 and
qwen3.5-27b.
Not long ago, the only models that could one-shot complex types on enterprise-scale projects were frontier ones. On the local side, DeepSeek v3.1 could one-shot mid-sized projects, but nothing larger — no one else even came close. Now, even a small model like qwen3.5-35b-a3b, the kind you can run at 4-bit on a consumer laptop with unified memory, lands enterprise-scale backends in a single shot. 100% compile success, with functional scores level with the frontier.
How should we read this leap? Two things came together. One is the harness effect from §4.1 — local models that struggled with complex types on the first attempt have, with retries and structured diagnostics behind them, settled into stable convergence. The other is the local-model camp’s own progress: a dense 27B today writes differently than a 27B did a year ago. The two compounded, and the gap with frontier is fast becoming a phrase that means less and less.
The harness mechanism itself is laid out in detail in the two posts below. The dashboard above is the empirical follow-through on what those two posts argued.
- https://dev.to/samchon/qwen-meetup-function-calling-harness-from-675-to-100-3830
- https://dev.to/samchon/function-calling-harness-2-cot-compliance-from-991-to-100-4f0h
4.3. Three Inversions Worth a Closer Look
Paired with the local-model surge is another current — though this one we’re more cautious about reading. Three results in this round run against the usual “newer and bigger means better” expectations.
GPT 5.4 scores below its own mini sibling. The phenomenon itself is documented in Function Calling Harness 2 — CoT Compliance : bigger and more frontier-tier models tend to follow CoT procedural instructions less reliably. GPT 5.4 happens to have this strongly enough that mini comes out ahead.
deepseek-v4-pro, after months of anticipation, lands in much the same place. It sits one notch below qwen3.5-35b-a3b (a model you can run at 4-bit on a laptop), and barely separates itself from its own Flash sibling — under one point apart. The Pro tier offers almost no advantage for the price.
Large-MoE plateaus follow the same shape. Within the Qwen family, the dense 27B (qwen3.5-27b) outscored every one of its MoE siblings (qwen3.5-35b-a3b, qwen3.5-122b-a10b, qwen3.5-397b-a17b), and the 17B-active 397B-A17B finished at exactly the same score as the 3B-active 35B-A3B.
How should these three be read together? We’re deliberately not jumping to a strong “newer and bigger isn’t the answer” claim. Two readings are live:
-
A real phenomenon, amplified by AutoBe’s setup. AutoBe’s pipeline leans heavily on function calling and CoT-style procedural enforcement, and the academic literature on CoT faithfulness — together with our own Harness 2 post — points to bigger, more frontier-tier models as the ones most likely to skip those procedures. If that effect is real, our setup naturally penalizes that class of model the most.
-
A flaw in the benchmark itself. n=4 reference projects, a 5-point score band, our own harness scoring our own pipeline. Variance and bias could be doing more of the work than we’d like, and we’d rather not over-claim before checking.
Which one dominates? We don’t know yet. We plan to keep digging — adding more reference projects, varying harness configurations, comparing runs with and without CoT enforcement — and we’ll report back in a future round.
For now the conservative reading is enough: rankings are decided within a single-digit gap, so “GLM beat the frontier” is a less accurate reading than “any model now produces roughly comparable results.”
And this is the last round we include frontier models in our comparison set.
5. May Onward — Local Models Only
Todo
qwen/qwen3.6-27b| Analyze | actors: 2, documents: 6 | |
| Database | namespaces: 2, models: 7 | |
| Interface | operations: 18, schemas: 27 | |
| Realize | functions: 27 | |
| Test | functions: 49 |
| Analyze | actors: 2, documents: 6 | |
| Database | namespaces: 7, models: 27 | |
| Interface | operations: 114, schemas: 102 | |
| Realize | functions: 162 | |
| Test | functions: 320 |
Shopping
qwen/qwen3.6-27b| Analyze | actors: 4, documents: 6 | |
| Database | namespaces: 2, models: 43 | |
| Interface | operations: 153, schemas: 198 | |
| Realize | functions: 240 | |
| Test | functions: 425 |
Erp
qwen/qwen3.6-27b| Analyze | actors: 2, documents: 6 | |
| Database | namespaces: 8, models: 21 | |
| Interface | operations: 95, schemas: 124 | |
| Realize | functions: 144 | |
| Test | functions: 274 |
With the gap gone, the decision follows. Starting next month, we stop benchmarking expensive frontier models. There’s no reason to pay frontier prices for the same output.
What made the decision easier, honestly, was cost. A single full-size project run (a shopping mall, say) burns roughly 200 to 300 million tokens. At GPT 5.5’s $5 per million input tokens, that’s $1,000–$1,500 per model, per run. With a benchmark that needs to run several models every month, that math just isn’t sustainable for an open-source project.
Local models, on OpenRouter, run tens of times cheaper. Or run them locally on a 64GB unified-memory laptop, and the cost essentially collapses to electricity. So from next round, the comparison set is restricted to models that meet one of two conditions:
- ≤ $0.25 per million input tokens on OpenRouter
- Locally runnable on a 64GB unified-memory laptop
Three candidates we’re locked in on so far:
openai/gpt-5.4-nano— $0.25 / Mqwen/qwen3.6-27b— $0.195 / Mdeepseek/deepseek-v4-flash— $0.14 / M
On this kind of model-discovery question, r/LocalLLaMA is faster than we are. So we plan to fill out a good chunk of next round’s comparison set from the comments on this post and from r/LocalLLaMA recommendations. If you know a model that meets either condition and has clean function-calling — a new low-cost endpoint on OpenRouter, or something that fits on a 64GB unified-memory laptop — let us know and we’ll add it.
Even if a model misses the conditions slightly, if you think “this one really needs to be benchmarked,” that’s welcome too. Expanding the comparison set isn’t a real cost issue (these are all small, cheap models). Good recommendations all eventually get tested.
6. Frontend Joins the Benchmark
That’s it for the backend side. In two or three months, another evaluation axis joins in — and these screenshots show what it’ll look like.
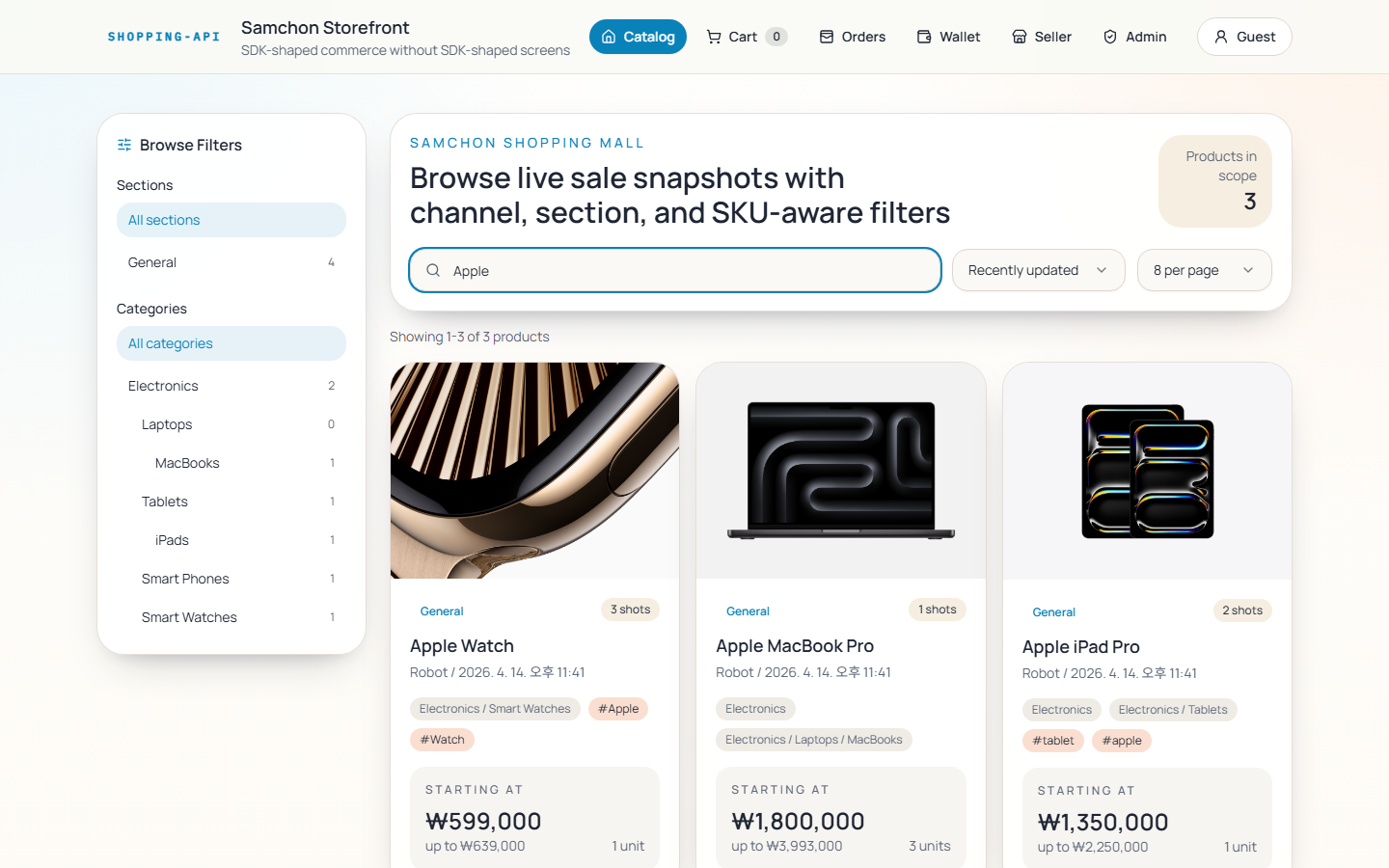
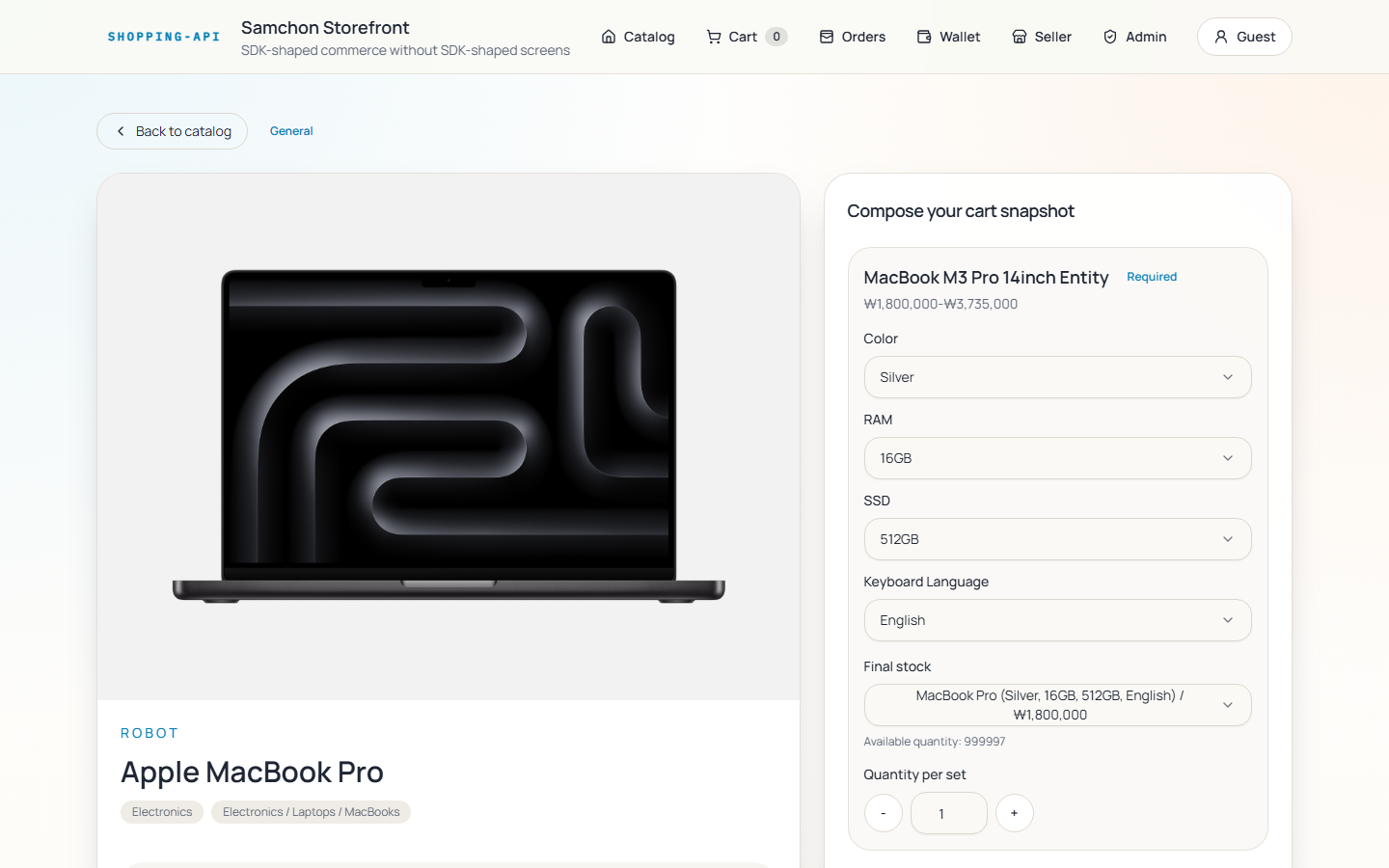
https://dev.to/samchon/nestia-well-designed-backend-fully-automated-frontend-development-45d9
The post above shows a case where, using nothing but the SDK that AutoBe generates, an entire frontend was auto-built end-to-end (reference repo: https://github.com/samchon/shopping ). The visual design doesn’t match handcrafted work, but every function works.
So from the June or July round onward, the benchmark covers both the backend and the auto-generated frontend together. The same cost reality applies — the comparison set will still be local-model-centric.
See you in the next round.